5. 教程: 临床数据统计#
在本节中,我们将学习如何执行描述性统计(descriptive statistics)、双样本 t 检验(two-sample t-test)以及非参检验(nonparametric test)。
在开始本节教程前,推荐掌握在软件中新建分析、载入仿例与运行分析等操作,可参考:开始使用 Maspectra。
若需了解示例数据、数据映射及链接数据等内容,可参考:数据处理与可视化、平均生物等效性计算。
5.1. 数据为什么需要统计?#
统计是一种生活工具、是一种理性认识世界的哲学观。透过统计,我们可以去定性或者定量地描述和测量这个世界。而临床数据的分析结果事关重大,更需要一种科学、理性的分析工具,统计学则恰好符合这样的需求。所以临床数据的分析离不开统计。
备注
若你想了解更多数理统计基础知识,可参考:
茆诗松, 程依明, & 濮晓龙. (2019). 概率论与数理统计教程(第三版). 高等教育出版社.
若你想了解更多临床试验有关的统计方法和知识,可参考:
陈峰 & 夏结来. (2018). 临床试验统计学. 人民卫生出版社.
5.2. 描述性统计#
描述性统计是指对数据的分布趋势、离散程度等进行描述和分析的统计方法。常见的统计量包括均值(mean)、标准差(standard deviation)、中位数(median)等。描述性统计是对数据最初的认识和探索。
接下来我们将对一个流行病学数据集进行受试者体重的描述性统计。
首先我们载入所需的示例数据集。右键左侧 “数据集”,在右键菜单中选择 “载入仿例数据”(图 5.1),在弹出的窗口中选择 “糖尿病患者数据集” (图 5.2)以导入带有糖尿病患者流行病学特征和血液指标的数据集供后续统计分析。
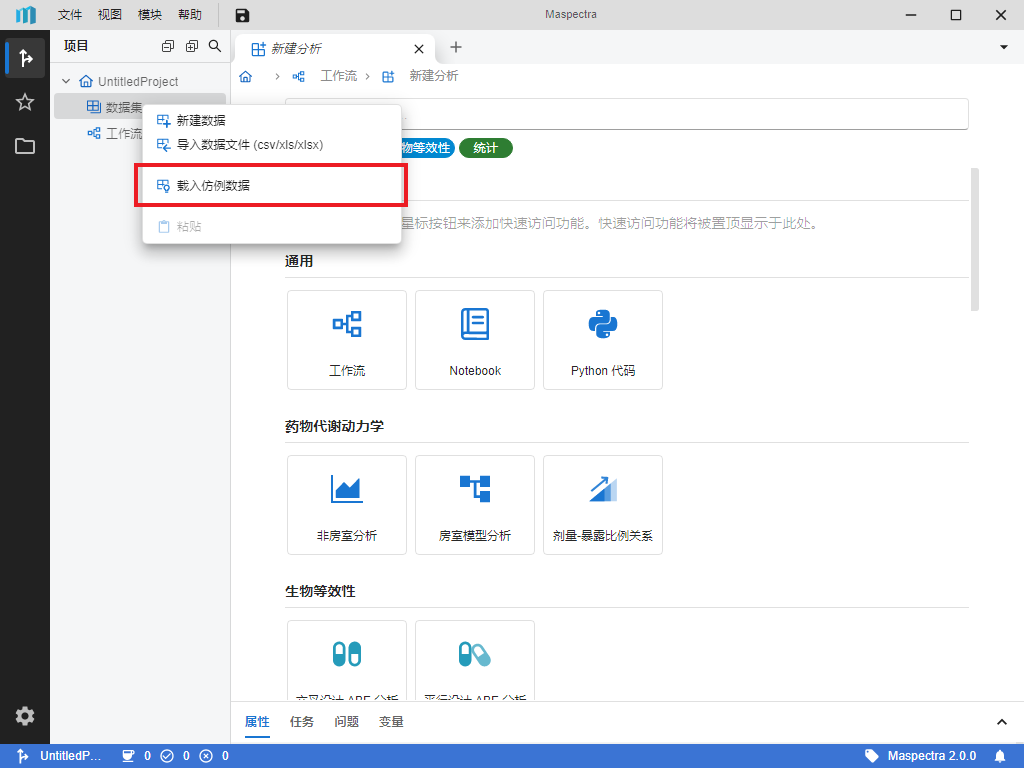
图 5.1 载入仿例数据选项示意图#
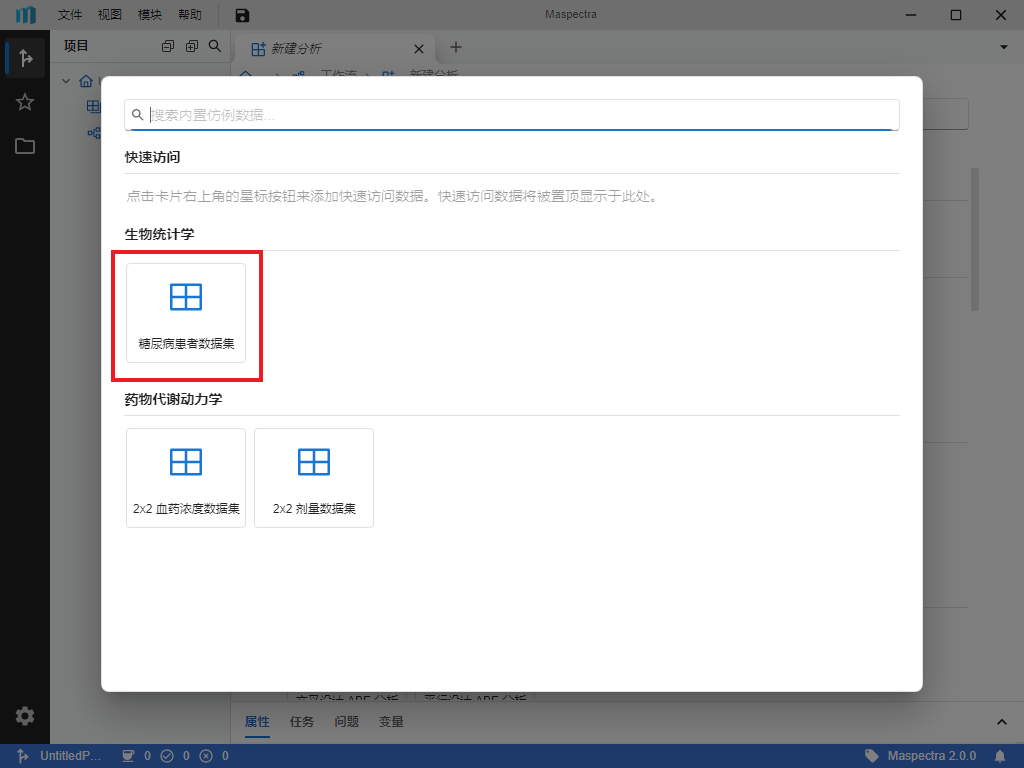
图 5.2 所需的仿例数据示意图#
导入完成后,在 “数据集” 中单击 “糖尿病患者数据集”,点击其标签页右上角
 按钮(图 5.3),在弹出的窗口中选择 “连续变量分析 > 描述性统计” (图 5.4)以创建描述性统计并链接数据。同样的,也可以将鼠标悬浮至数据集上,并点击右侧的
按钮(图 5.3),在弹出的窗口中选择 “连续变量分析 > 描述性统计” (图 5.4)以创建描述性统计并链接数据。同样的,也可以将鼠标悬浮至数据集上,并点击右侧的 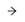 按钮来以完成上述操作。
按钮来以完成上述操作。
图 5.3 新建分析选项示意图#
图 5.4 “描述性统计” 选项示意图#
在描述性统计数据页中的 “链接数据” 模式下,将
BMI(即身体质量指数)映射至 “变量”(图 5.5)。
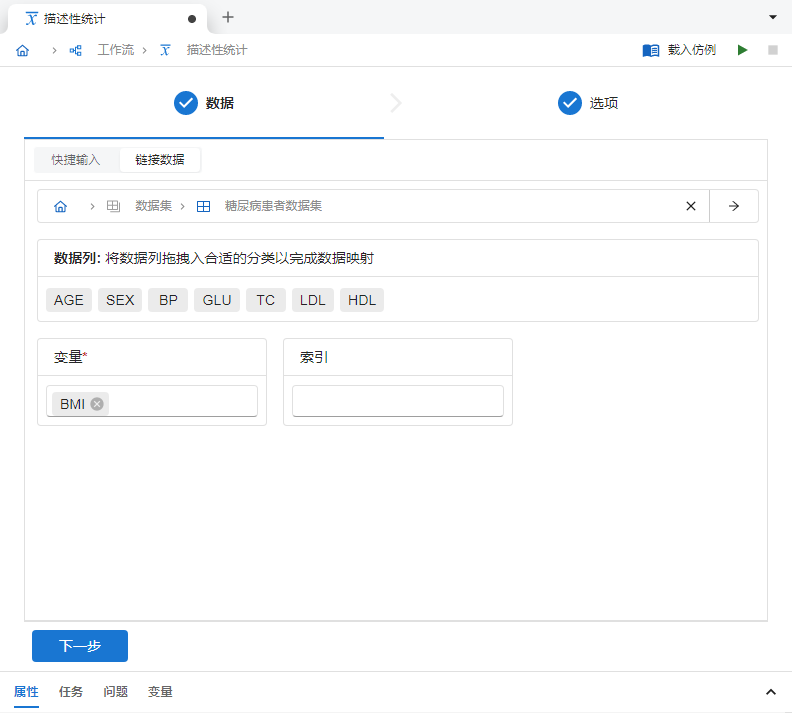
图 5.5 描述性统计数据映射关系示意图#
完成映射后,点击底部 “下一步” 按钮(或标签页顶部 “选项” 按钮)前往描述性统计选项页。在此选项页中,我们可以通过勾选的方式来决定需要计算的统计量。为了更好地了解患者 BMI 的分布情况,除默认选项外,我们勾选 “样本方差” 与 “四分位数” 选项(图 5.6)。
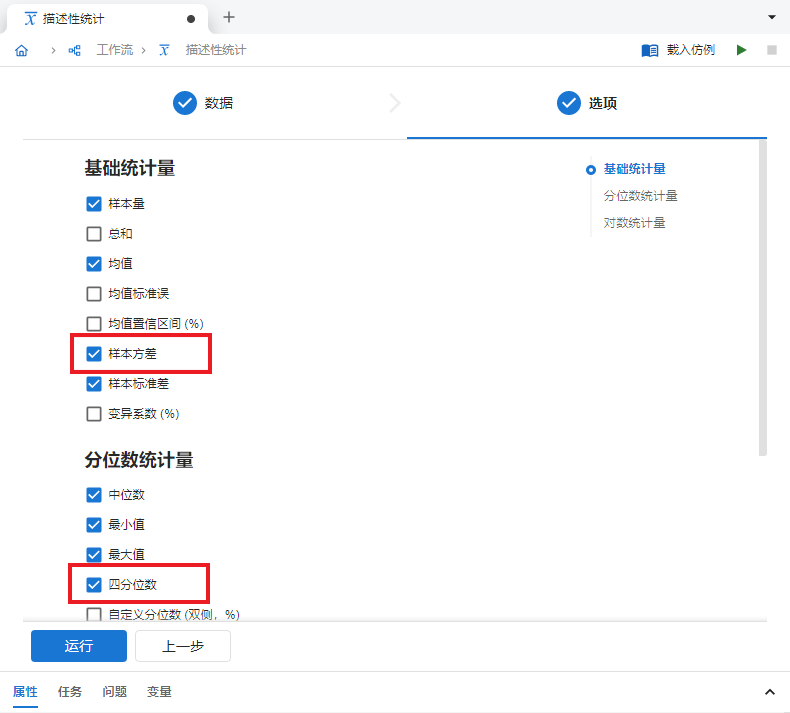
图 5.6 描述性统计选项设置示意图#
完成设置后,点击右上角
 按钮或底部 “运行” 按钮,即可运行描述性统计。
按钮或底部 “运行” 按钮,即可运行描述性统计。运行完成后,可在描述性统计的 “结果” 页内查看统计结果。可以发现受试者的 BMI 均值约为 26 m/kg^2、中位数约为 25 m/kg^2(图 5.7)。这一结果表明此数据中患者存在超重的情况,提示我们糖尿病发病与肥胖可能有潜在相关性。
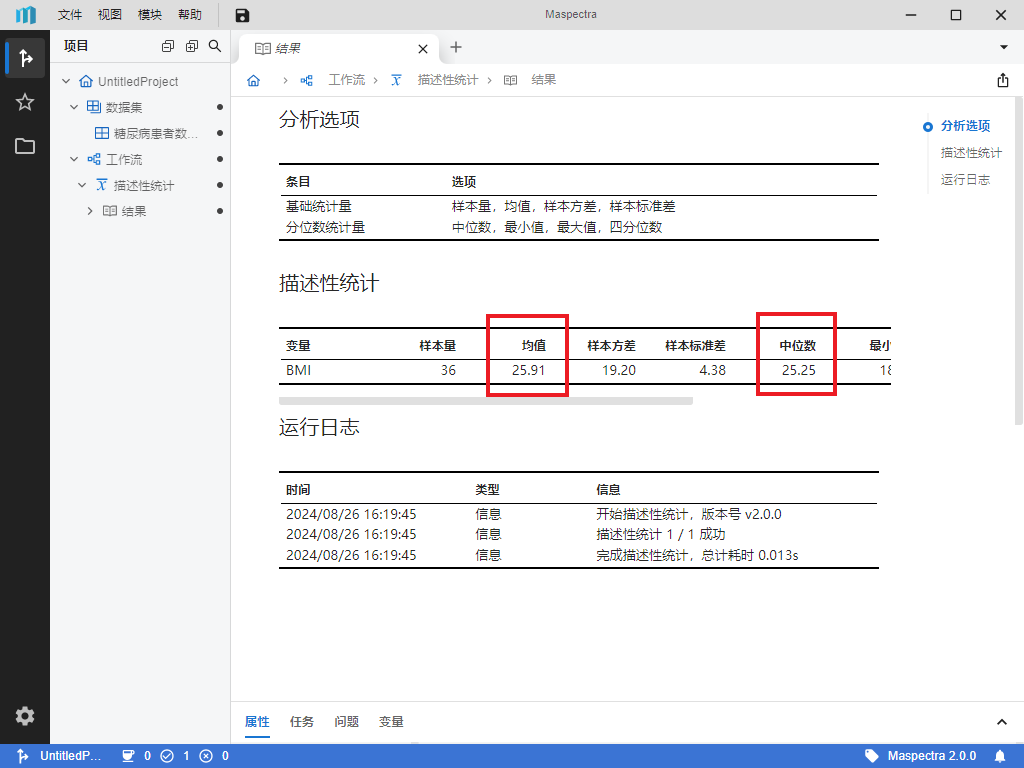
图 5.7 描述性统计统计结果示意图#
5.3. 双样本 t 检验#
t 检验(student's t-test)是一种可以评估和比较总体均值的统计检验方法。其中的双样本 t 检验可用于评估两个组的均值是否有显著差异。
接下来我们将检验上述数据集中不同性别受试者的空腹血糖值是否有显著性差异。
类似于创建描述性统计的流程,单击 “数据集 > 糖尿病患者数据集” ,点击其标签页右上角
按钮(图 5.3),在弹出的窗口中选择 “连续变量分析 > 双样本 t 检验” (图 5.8)以创建双样本 t 检验。
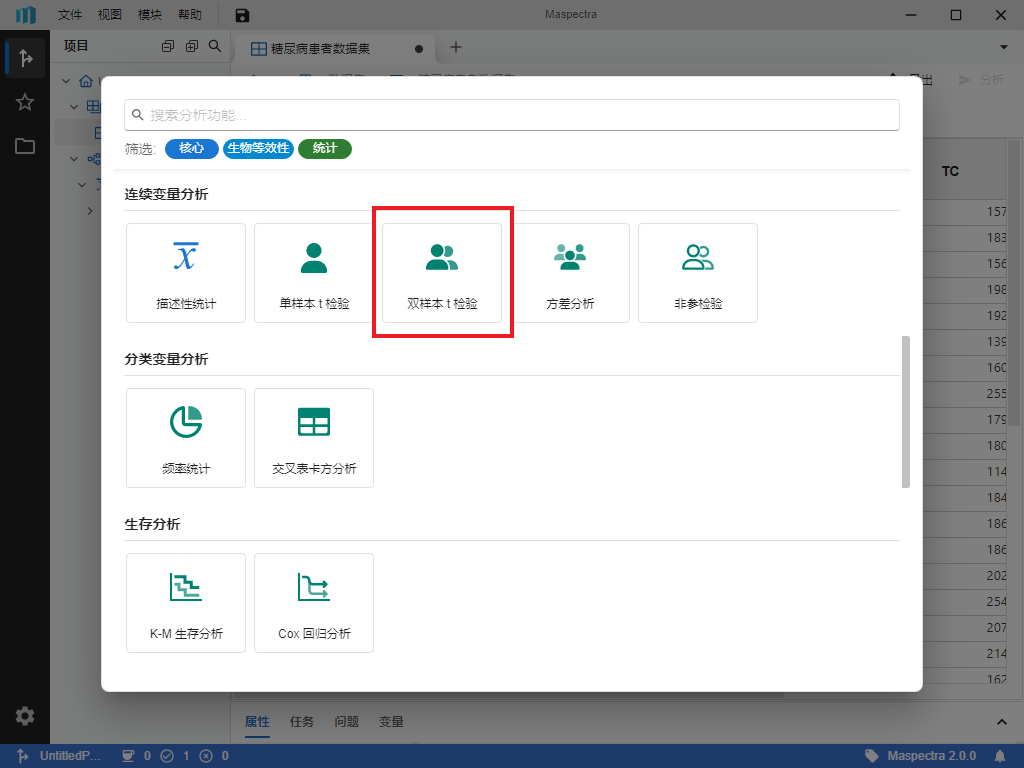
图 5.8 “双样本 t 检验” 选项示意图#
创建完成后,我们在双样本 t 检验数据页 “链接数据” 中将
GLU(即空腹血糖值)列映射至 “变量”、SEX(即患者性别)列映射至 “组别”(图 5.9)。
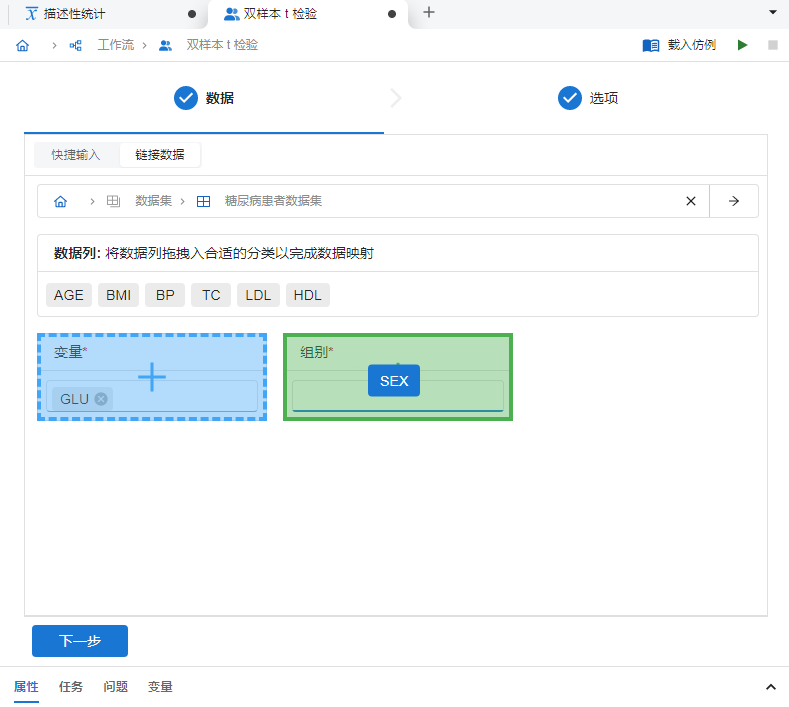
图 5.9 双样本 t 检验数据映射关系示意图#
完成数据映射后,点击底部 “下一步” 按钮(或标签页顶部 “选项” 按钮)至双样本 t 检验选项页。在此选项页中,我们可以在 “组别定义” 内选择需要比较的组别,可选的组别来源于被映射为 “组别” 的数据列(在本例中,即
SEX列)中的数据。我们在 “组一” 和 “组二” 内分别选择F与M来比较不同性别间的体重差异(图 5.10)。
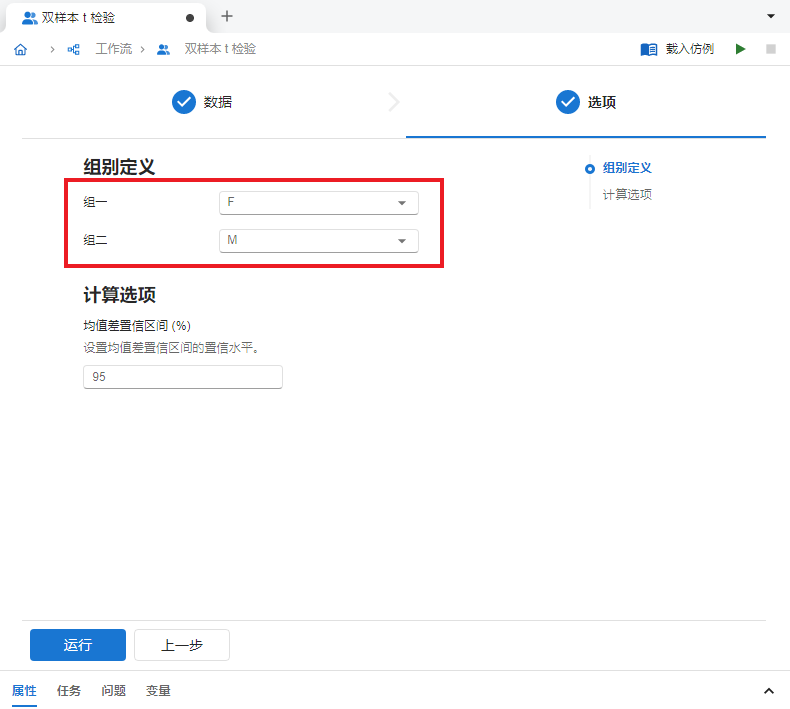
图 5.10 双样本 t 检验选项设置示意图#
输入完成后,点击右上角
按钮或底部 “运行” 按钮,即可运行双样本 t 检验。运行完成后,可在双样本 t 检验的 “结果” 页内查看结果。我们可以发现不同性别患者血糖值均值差为 7.4 mg/dL, P 值小于 0.05(图 5.11),可以认为不同性别患者的血糖值存在显著差异。
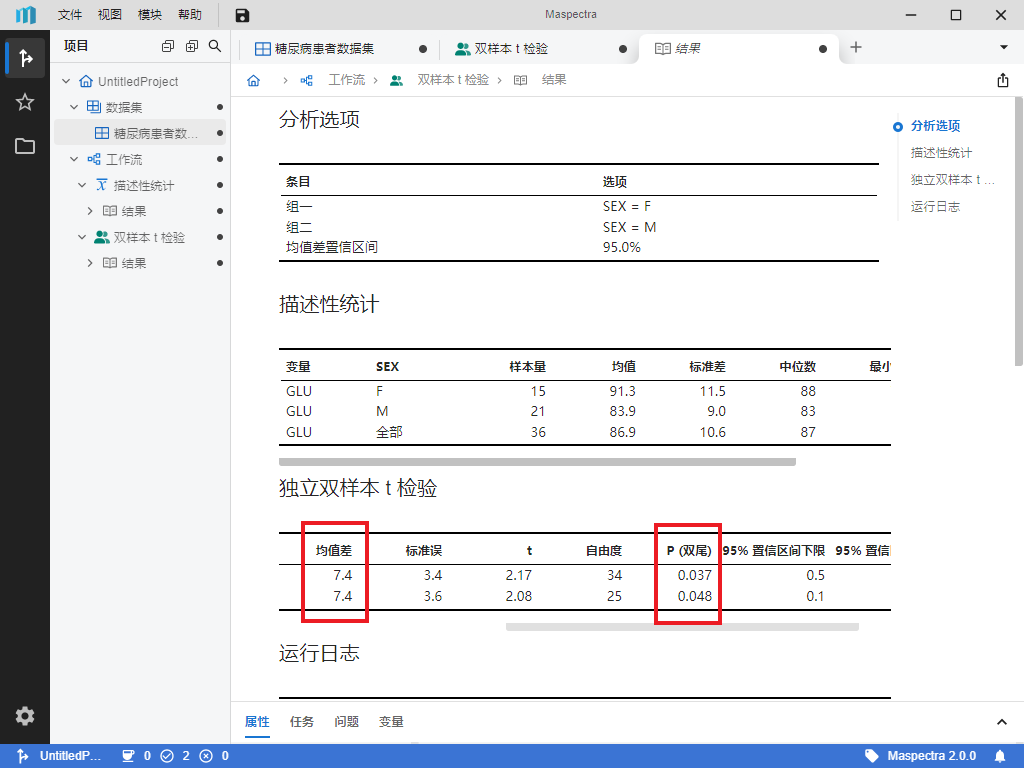
图 5.11 双样本 t 检验统计结果示意图#
5.4. 非参检验#
非参检验(nonparametric test)是统计检验方法的一个重要组成部分,常见的非参检验方法包括 Mann-Whitney U 检验、Wilcoxon 检验等;与参数检验(例如 t 检验)不同,非参检验不需要假设数据分布的正态性。在临床试验中经常存在不一定符合正态分布的数据,例如患者年龄、量表分数等。因此,在临床数据统计分析过程中,非参检验也有很大的应用空间。
接下来我们将继续基于上述糖尿病患者数据集,使用非参检验的方法比较不同性别的受试者年龄是否有显著差异。
与上述两个案例相同,相信你已经非常熟悉新建分析的流程了。我们可以单击 “数据集 > 糖尿病患者数据集” ,点击其标签页右上角
按钮(图 5.3),在弹出的窗口中选择 “连续变量分析 > 非参检验” (图 5.12)来创建非参检验。也可以用右键菜单的方式来创建非参检验。
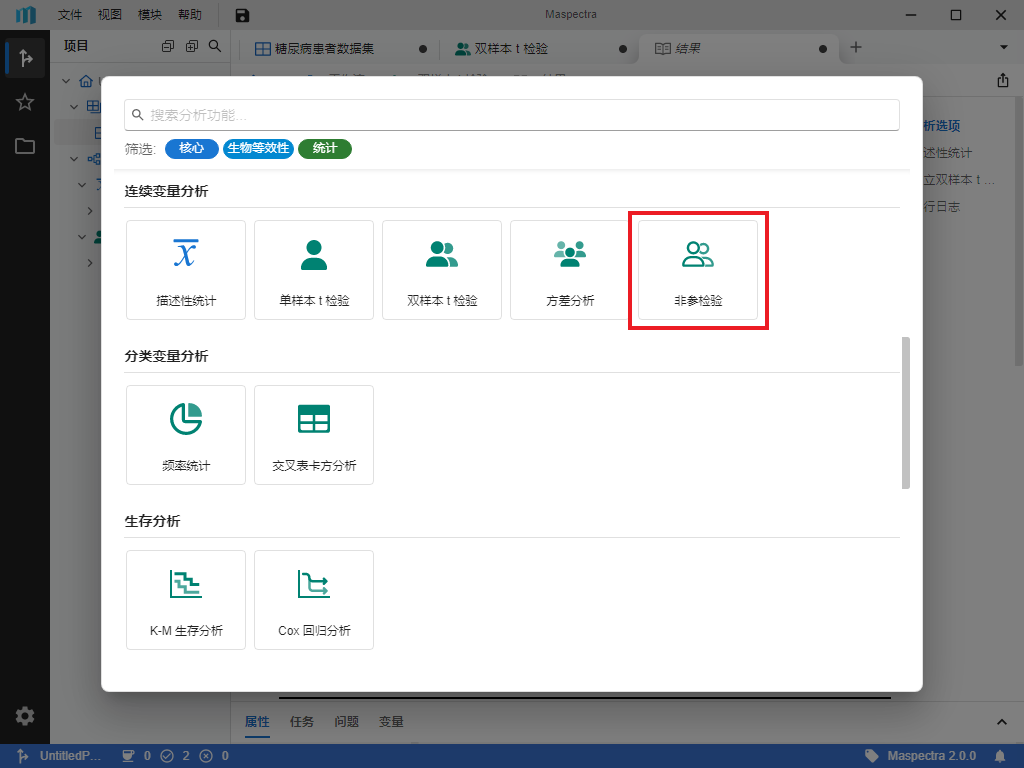
图 5.12 “非参检验” 选项示意图#
创建完成后,我们在非参检验数据页 “链接数据” 中将
AGE(即受试者年龄)映射至 “变量”(我们假设年龄不符合正态分布);将SEX(即受试者性别)映射至 “组别” 来实现后续的组间比较(图 5.13)。
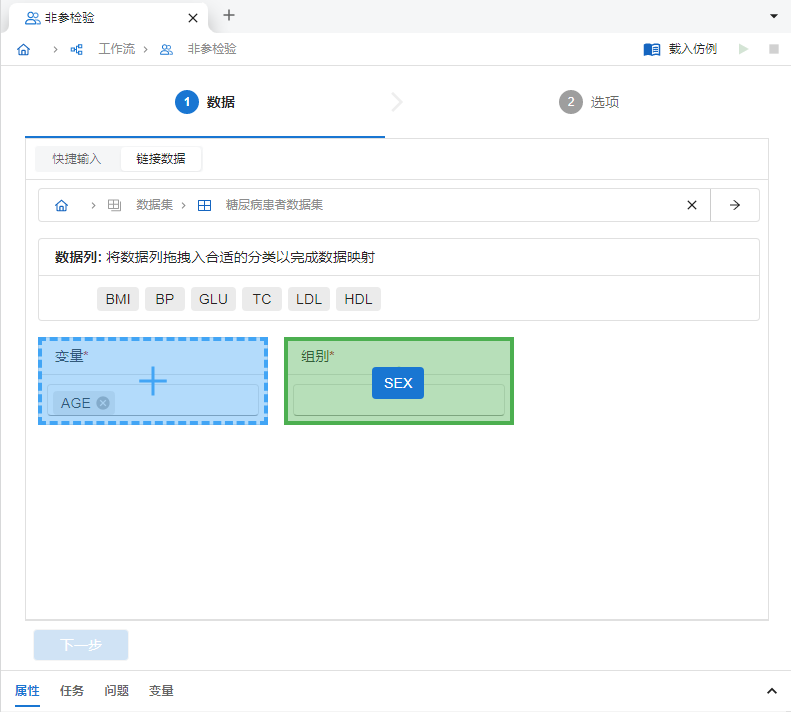
图 5.13 非参检验数据映射关系示意图#
映射完成后,我们点击底部 “下一步” 按钮(或标签页顶部 “选项” 按钮)前往选项页。在非参检验的选项页中,和 双样本 t 检验 中的操作类似,我们可以在 “组别定义” 中指定 “组一” 为
F、“组二” 为M,即比较F(女性)与M(男性)组的年龄差异(图 5.14)。
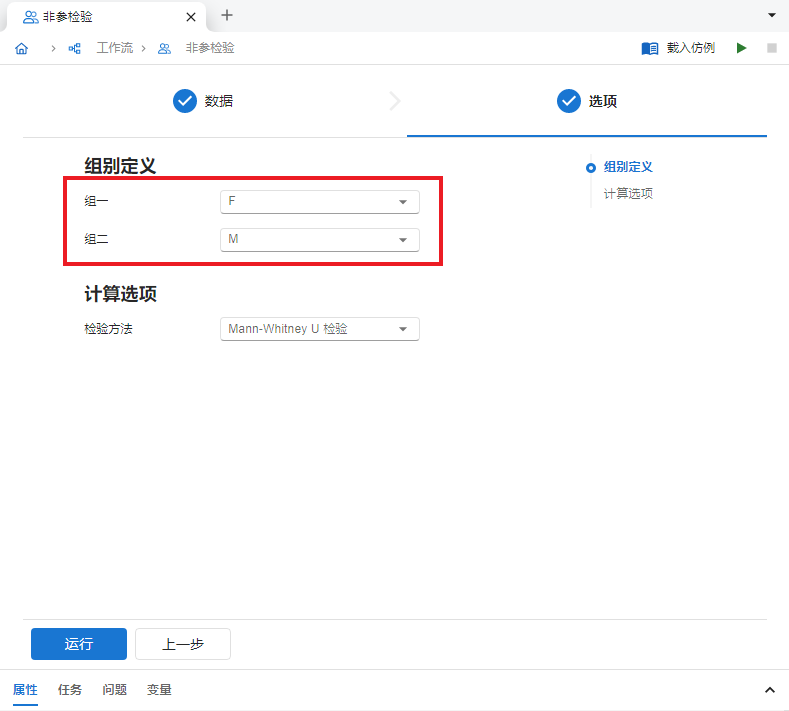
图 5.14 非参检验选项设置示意图#
设置无误后点击右上角
按钮或底部 “运行” 按钮,即可运行非参检验。运行完成后,我们进入非参检验 “结果” 页查看统计结果。检查 “独立双样本 Mann-Whitney U 检验” 表格,我们可以发现 P 值小于 0.05(图 5.15),说明不同性别受试者的年龄存在显著差异。这一结果提示在后续临床试验结果分析过程中不同性别受试者的试验结果中可能存在由年龄导致的偏倚。
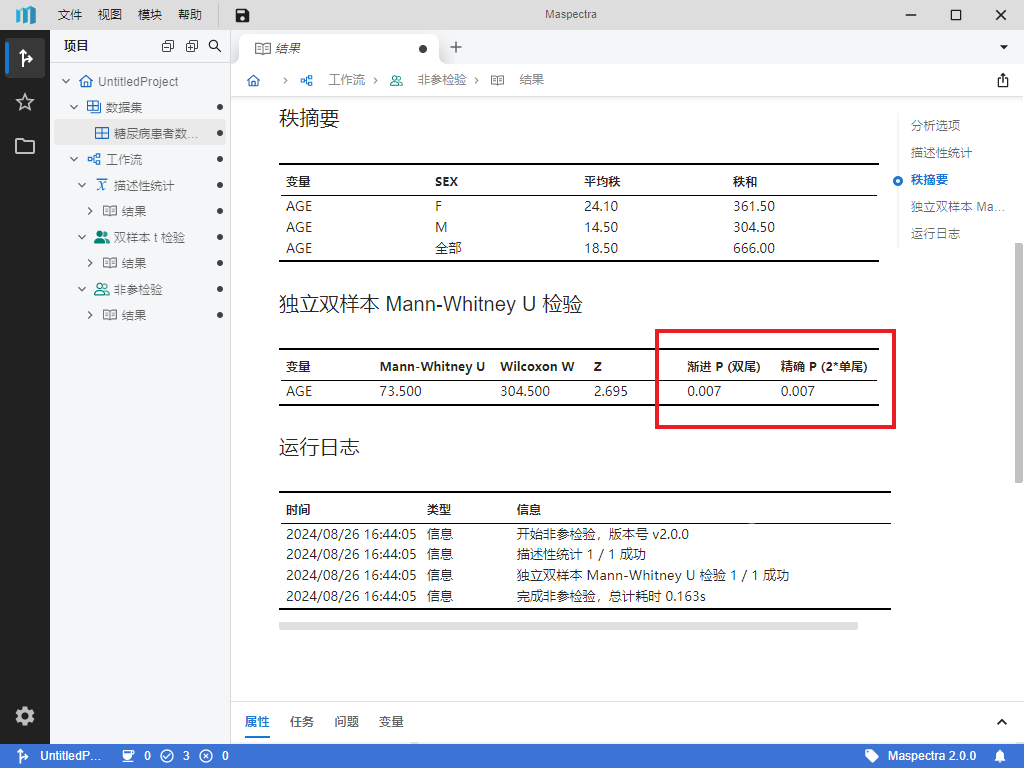
图 5.15 非参检验统计结果示意图#