1. Python 编程语言入门#
在阅读本节之前,我相信你一定听说过 Python——世界上使用最为广泛和知名的编程语言之一。
Python 因为其优雅、明确、简单的定位,使得其非常适合于应用开发以及数据科学研究,目前也已经被大量应用于机器学习与人工智能领域。也正是因为使用的广泛性,使得 Python 中存在非常完整的数据科学生态,让我们在研究时可以“开箱即用”。
综上所述,我们选择了 Python 作为构建 Masmod 模型的语言。在接下来的十分钟里,我们会通过数个简单的例子来入门 Python。
小技巧
你可以使用我们软件中的 Notebook 功能来亲手尝试编写和运行下方的代码。
1.1. Hello, World!#
首先,和所有的编程语言教程一样,我们来使用 Python 打印 Hello, World!
print("Hello, World!")
Hello, World!
1.2. 注释#
在编写任何代码和程序时,注释也是非常重要的,因为恰当的注释可以提示你或其他读者这段代码的功能。在 Python 中,注释使用井号 # 开头(如果你写过 NONMEM 控制文件,# 的用法和含义与控制文件中的 ; 类似)。
使用平易近人的语言编写注释,但也不要过度使用注释。时刻谨记会阅读你代码的人(当然也包括几年后的你自己)远比真正需要运行它的人多。优秀的注释可以在很大程度上帮你避免自己看不懂自己代码的情况。
print("Hello again")
# 在 Python 中,使用 print 来打印文本
Hello again
小技巧
你也可以使用注释来临时禁用一段代码。
1.3. 运算符#
1.3.1. 数学运算符#
Python 和一般的编程语言一样,支持许多的运算符。接下来先简单介绍一下最常用的数学运算符号,他们和平时书写数学公式时所用的符号基本一致:
print(100 + 200) # 加法运算
print(200 - 100) # 减法运算
print(3 * 4) # 乘法运算
print(8 / 4) # 除法运算
print(2**3) # 指数运算
print(10 // 2) # 整除运算
print(10 % 3) # 取余运算
300
100
12
2.0
8
5
1
1.3.2. 逻辑运算符#
Python 也支持一系列的比较运算符,例如 ==、!= 等。比较运算的结果是一个布尔值(boolean),布尔值只包含两种值,即真 True 或假 False。
print("100 < 200 是", 100 < 200) # 小于运算
print("200 > 100 是", 200 > 100) # 大于运算
print("300 <= 200 是", 300 <= 200) # 小于等于运算
print("50 >= 200 是", 50 >= 200) # 大于等于运算
print("100 == 101 是", 100 == 101) # 等于运算
print("100 != 101 是", 100 != 101) # 不等于运算
100 < 200 是 True
200 > 100 是 True
300 <= 200 是 False
50 >= 200 是 False
100 == 101 是 False
100 != 101 是 True
接下来是另一些布尔值相关的逻辑运算:
and为逻辑与运算符,相当于“而且”的意思,只有当两边的条件都同时为True的情况下运算结果才为True。反过来说,只要有一个条件为False,运算结果就是False。or为逻辑或运算符,相当于“或”的意思,当两个条件只要有一个为True运算结果就为True。not为逻辑非运算符,可以返回当前布尔值的相反值。True的相反值就是False,反之亦然。
print("True and True 是", 100 < 200 and 200 > 100) # 与运算
print("True or False 是", 100 < 200 or 100 > 200) # 或运算
print("not True 是", not 1 == 1) # 非运算
True and True 是 True
True or False 是 True
not True 是 False
1.4. 变量与赋值#
在 Python 中使用变量(variable)来存储数据,通过访问其变量名便可以调用其中的数据。
使用赋值符 = 可以给变量赋值。
n_cats = 100
print("总共有", n_cats, "只猫。")
总共有 100 只猫。
需要注意区分赋值符与数学中的等号的不同。尝试观察以下代码的结果:
x = 10
x = x + 5 # 先计算右侧的 10 + 5,再将其赋值给 x
print(x)
15
Python 中对变量名有一定的约束:
变量名只能由大小写英文字母、数字和
_组成。变量名不能用数字开头
例如以下的变量名是不合规的:2var、my-name、this is space。
小技巧
一个好的变量名可以使你或读者更容易记住和理解代码。
1.5. 分支结构与循环结构#
在 Python 我们可以使用 if 来定义一些具有分支结构的代码块。使用 for 或 while 则可以定义一些循环结构。
使用分支结构我们可以根据条件的不同而控制代码走向的不同,例如玩游戏时根据玩家分数大小来决定奖励多少的机制就是一个典型的分支结构。
而循环结构则和其字面意思一致,可以重复执行其中的代码。例如使用循环结构,我们可以快速的计算 0~100 的整数的总和。
1.5.1. 分支结构#
下面是一个具有分支结构的代码样例。当存在多个需要判断的条件时,可以使用 else 与 elif。
在运行下方代码前,你可以尝试猜测最终的输出结果是什么。也可以试着修改 cats 与 dogs 的赋值,观察结果是否会有不同。
n_cats = 10
n_dogs = 5
if n_cats > n_dogs:
print("猫太多了!")
elif n_cats < n_dogs:
print("狗太多了!")
else:
print("恰好相等。")
猫太多了!
重要
在 Python 语法规则中,只要一行以冒号 : 结尾,其接下来的内容应当有缩进。一般每一级的缩进量为 4 个空格。
1.5.2. for 循环#
下面的代码是一个 for 循环结构的样例。循环的条件一般用 for 开头,用 in 表示循环的范围。
# 计算 0~100 的整数的总和
sum = 0
for i in range(0, 101): # range 的取值范围是前开后闭的区间
sum = sum + i
print(sum)
5050
1.5.3. while 循环#
当你不能确切的知道循环范围或次数的时候,可以使用 while 循环。while 循环的循环条件是一个布尔值,只有当其是 False 时才会停止循环。
# 打印 1~10 内的偶数
x = 1
while x <= 10:
if x % 2 == 0:
print(x)
x += 1 # 等价于 x = x + 1
2
4
6
8
10
当我们想要提前中止循环时,可以使用 break 关键字来跳出当前循环:
# 求 1~20 内 3 的倍数
x = 1
while True:
if x > 20:
break
if x % 3 == 0:
print(x)
x += 1
3
6
9
12
15
18
1.6. 函数#
1.6.1. 函数定义和调用#
函数(function)是对代码块的一种封装。通过调用函数,我们可以避免大段的重复代码。
在数学中,其实这样的封装极为常见,例如求和符号 \(\Sigma\) 就是对写起来十分不便的 \(1 + 2 + 3 ...\) 的一种封装。
在 Python 中,我们使用 def 来创建一个函数。创建完成后,使用 函数名() 就可以调用这个函数。例如一开始我们使用的 print 就是一个函数。
def print_hello():
print("使用函数打印 Hello.")
print_hello()
使用函数打印 Hello.
备注
函数的命名规约与变量一致。同样的,也建议使用自明性较强的函数名。
1.6.2. 函数的参数#
函数也能拥有一些参数(arguments)。参数即我们传入给函数的值,以便于函数对这些传入值进行一些操作或运算以取得我们所需的结果。
参数在函数定义时的括号 () 内指定,多个参数用逗号 , 来隔开。当我们调用函数的时候,我们也以同样的方式提供参数值。
同样的,可以用求和符号 \(\Sigma\) 来理解参数的概念。参数即类似于 \(\Sigma\) 的上下标,通过指定上下标的值,我们就可以知道需要求和的范围,例如 \(\sum_{i=0}^{100}\) 就是对 0~100 的求和。
def sum(start, end):
res = 0
for i in range(start, end + 1):
res = res + i
print(res)
sum(start=0, end=100)
5050
在上述函数调用时,我们直接通过关键字(即参数名)传入了参数值。我们也可以在调用函数时省去关键词,直接按参数的位置顺序传入参数值。通过这两种方式传入的参数分别被称为关键词参数(keyword argument)和位置参数(positional argument)。
例如以下的函数和 sum(start=0, end=100) 是等价的:
sum(0, 100)
5050
重要
上述两种方法可以同时使用。但注意,关键字参数必须在位置参数之后。例如以下代码是错误的:
sum(start=0, 100)
^
SyntaxError: positional argument follows keyword argument
我们也可以通过 函数名 (参数名=默认值) 的方法来指定参数的默认值。在函数调用时,若未传入参数值,则将使用默认值。
def sum(start=0, end=100):
res = 0
for i in range(start, end + 1):
res = res + i
print(res)
sum()
5050
1.6.3. 函数的返回值#
使用 return 我们可以指定函数的返回值(即函数的计算结果)并跳出函数。合理地定义和使用返回值可以方便我们获取和操作函数的计算结果。
def fac(x):
"""阶乘运算。
x: int
需要计算其阶乘的正整数。
"""
if x > 0:
res = 1
for i in range(1, x + 1):
res *= i
return res
elif x == 0:
return 1
else:
raise ValueError("只能对非负数求阶乘")
n = fac(5)
n
120
小技巧
在 Python 中通过关键词 raise 抛出异常。
相信你已经注意到了上述代码中的 """。使用三个引号可以定义文档字符串(DocStrings)。文档字符串类似于一个多行的注释,可以对函数的功能以及使用方法提供一个整体的描述。
小技巧
如果你正在使用我们软件的 Notebook 进行上述代码的练习,试着将鼠标悬停到 fac 上,你可以发现在悬浮窗上能看到你已撰写的文档字符串(图 1.39)。这也是文档字符串和一般注释的不同点之一,它是可以通过某种方式被调用的(例如使用 help() 函数)。
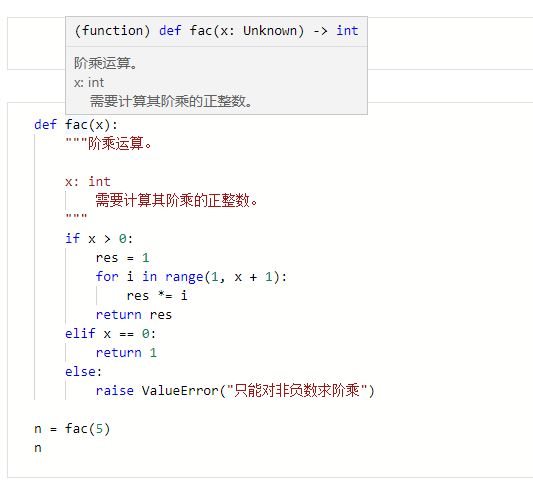
图 1.39 文档字符串悬停提示示意图#
1.7. 列表和字典#
列表(list)和字典(dictionary)是 Python 中最常用的数据结构之一。数据结构是存储数据的方式,选择合适的数据结构可以使编程更为简单:例如使用列表可以帮助我们存储大量的数据并获取某一个位置的对应值。
1.7.1. 列表#
列表可以帮助我们存储一系列有序的数据,其中的每个数据被称为元素(element)。
使用 [] 来创建一个列表,并将它的元素置于其中。多个元素使用 , 进行分隔。
animals = ["cat", "dog", "elephant", "dolphin"]
print(animals)
['cat', 'dog', 'elephant', 'dolphin']
由于每个列表内的元素是有序排列的,我们可以通过 列表变量[位置] 的方式来取得某个位置的元素的值。这里指代元素位置的值一般被称为索引值(index)。在下方代码中,可以尝试修改索引值来得到不同的结果(例如可尝试负整数)。
animals = ["cat", "dog", "elephant", "dolphin"]
print(animals[3]) # 取出第四个元素
dolphin
重要
在 Python 中,索引值是从 0 开始的。也就是说,若要取得第一个元素值,需要使用 [0]。
而在 R 中,索引值从 1 开始,需要对两种语言的不同进行区分。
如果要取出若干个元素,则可以使用切片操作 [起始位置 : 中止位置]。注意,和 range 一样,切片的取值范围为前开后闭区间,也就是说,不包括索引值等于中止位置的元素。
animals = ["cat", "dog", "elephant", "dolphin"]
print(animals[1:3]) # 取出第二到第三个元素
print(animals[1:]) # 取出第二个到最后一个元素
print(animals[:2]) # 取出第一个到第二个元素
print(animals[:]) # 取出所有元素
['dog', 'elephant']
['dog', 'elephant', 'dolphin']
['cat', 'dog']
['cat', 'dog', 'elephant', 'dolphin']
也可以通过一些函数来对列表中的元素进行增删改查:
animals = ["cat", "dog", "elephant", "dolphin"]
animals.append("penguin") # 在末尾增加元素
print(animals)
animals.pop(0) # 移除第一个元素
print(animals)
animals[-1] = "panda" # 修改最后一个元素的值
print(animals)
animals.insert(1, "whale") # 在索引为 1 的地方插入元素
print(animals)
print(len(animals)) # 获取列表的长度(元素个数)
['cat', 'dog', 'elephant', 'dolphin', 'penguin']
['dog', 'elephant', 'dolphin', 'penguin']
['dog', 'elephant', 'dolphin', 'panda']
['dog', 'whale', 'elephant', 'dolphin', 'panda']
5
1.7.2. 字典#
使用字典也可以存储一系列的数据。和列表不同,字典的每一个元素都是一对键值对(key-value),反应了两组物件之间一一对应的关系。我们可以通过输入键值来取得其对应的数据值——和现实生活中的字典一模一样。
使用 {} 来创建字典,用 键: 值 的形式来创建键值对,多个键值对使用 , 隔开。
animal_counts = {"cat": 20, "dog": 10, "elephant": 3}
print(animal_counts)
{'cat': 20, 'dog': 10, 'elephant': 3}
和列表的索引取值类似,可以使用 [键] 的方法来获取某个键对应的数据值:
animal_counts = {"cat": 20, "dog": 10, "elephant": 3}
print(animal_counts["cat"])
20
和列表类似,也可以对字典进行增删改查:
animal_counts = {"cat": 20, "dog": 10, "elephant": 3}
animal_counts["cat"] = 25 # 修改键对应的值
print(animal_counts)
animal_counts.update(dolphins=10) # 增加键值对
print(animal_counts)
animal_counts.pop("cat") # 删除键值对
print(animal_counts)
{'cat': 25, 'dog': 10, 'elephant': 3}
{'cat': 25, 'dog': 10, 'elephant': 3, 'dolphins': 10}
{'dog': 10, 'elephant': 3, 'dolphins': 10}
1.8. 使用模块和包#
Python 的一大特点便是拥有众多优秀的内置模块和第三方数据科学包。在 Python 中,一般将每个独立的 .py 文件称为一个模块(module)。同一个文件目录下的各个模块,组成一个包(package)。通过导入不同的包或者模块,可以使我们直接调用其中的函数或内容。
我们使用 import 语句来导入一个模块。我们来试试引入第三方模块 “numpy”:
import numpy
如果模块的名太长,我们也可以用 import ... as ... 的方法来给模块一个别名:
import numpy as np
a = np.array([1, 2, 3])
如果你需要从某个包中导入模块,可以使用 from ... import ...。例如我们来尝试导入 Masmod 内置的口服一房室模型:
from mas.model import EvOneCmtLinear
你可以使用我们的 群体药动学建模入门案例 来进一步熟悉导入的操作。
如果你熟悉 R 语言,那其实 Python 中的 import 与 R 中的 library("") 类似,但是更为灵活。
1.9. 面向对象编程#
在我们 Masmod 的建模框架中使用了许多面向对象(Object Oriented)的编程方法,而且在调用其他 Python 第三方包(例如机器学习框架 PyTorch)的过程中也需要掌握面向对象的使用,所以接下来我们将简单讲解一下面向对象编程。
面向对象编程是一种编程思想与方法。首先我们会将世间的事物视为一个个的对象(object),这些对象有自己各自的特性或行为(例如每个人有自己的名字),对一些具有共同特性或行为的对象的概括或抽象(在编程中也被称为封装,在上文的 函数 小节中也有这个概念)可以称为一个类(class)。例如老师、学生、工人都是对一类人的统称,这些称呼就类似于面向对象中的类的概念。
例如我们将“人”这个概念抽象为一个类 People。在 Python 中,我们通过 class 类名 来创建一个类。
class People:
pass
而类中每一个具体存在的对象我们称为实例(instance),我们来试着创建一个 People 的实例,即一个具体的人:
tom = People()
每个人都有自己的名字,这一特性我们可以抽象至 People 这个类中。在编程中,对象的这些特性一般称为“属性”(property)。接下来我们来添加 name 这个属性:
class People:
def __init__(self, name):
self.name = name
上文中的 __init__ 表明了此函数在实例创建的时候就会被调用。
此外我们也注意到了凭空出现的 self,self 是实例本身的指代,就是中文中 “我” 的意思(专业的讲,self 是实例的引用)。通过 self 和 __init__ 的一起使用,我们可以将属性在实例创建时就绑定至实例上。
和函数传入参数的方法一致,我们在实例化时用 类名(属性=属性值) 的方法传入实例的属性。通过 .属性名 来调取实例的属性。例如我们现在就可以调取创建的实例的 name 属性了:
jerry = People(name="jerry")
print(jerry.name)
jerry
除了属性外,我们也可以为每个类定义一些行为,例如人会走路、游泳等。这些行为被称为方法(method),它们可以被视作一系列的函数,定义它们的写法也与定义函数的写法类似,不过记得参数列表内需要 self:
class People:
def __init__(self, name):
self.name = name
def work(self):
print(self.name, "can work.")
调用类方法的写法与调用属性一致,使用 .:
jerry = People(name="Jerry")
jerry.work()
Jerry can work.
在现实世界中,不同的类之间可能具有从属关系,例如学生、老师、工人都从属于人这个概念。在面向对象中,这样的关系称为继承(inherit),合理地使用继承可以帮助我们快速构建派生类。例如我们定义一个学生类 Student:
class Student(People):
def __init__(self, name):
super().__init__(name)
jack = Student(name="Jack")
jack.work()
Jack can work.
很明显学生从属于 People 这个类,具有其所有的特性。我们称类似于 Student 的类为子类,People 此种被继承的类为父类。我们用 子类名(父类名) 的方法来定义继承关系。继承而来的 Student 类拥有 People 中定义的所有属性和方法。
备注
使用 super().__init__() 可以调用继承而来的父类 __init__() 方法,避免在继承时频繁复制代码。
此外,继承关系还有一个优势,就是在子类调用父类属性或方法时,无须知道其中的实现细节,因为在父类中我们已经完成了抽象与封装。我们在实际编程过程中也可以体会到这种便利性,例如,我们可以让模型继承 mas.model.EvOneCmtLinear 来使用 Masmod 内置的一室口服模型,而不需要自己手动编写房室模型微分方程的闭式解。相关的例子可见:群体药动学建模入门案例。
就如现实生活一样,每类人都有不同之处,例如老师与学生的工作内容就各不相同。在面向对象中,我们可以为每个子类增加独有的属性或方法,也可以重写继承而来的方法,这样的概念我们称为多态(polymorphic),即同一个方法由于对象的不同而产生不同行为的现象。例如,我们可以重写 Student 和 Teacher 类的 work 方法:
class Student(People):
def __init__(self, name):
super().__init__(name)
def work(self):
print(self.name, "can study.")
class Teacher(People):
def __init__(self, name):
super().__init__(name)
def work(self):
print(self.name, "can teach students.")
mary = Student(name="Mary")
mary.work()
petter = Teacher(name="Petter")
petter.work()
Mary can study.
Petter can teach students.
综上所述,我们已经了解了面向对象的三大特性:封装、继承与多态。与面向过程编程不同,使用面向对象思想编写程序时,需要最大程度地考虑对不同对象的抽象与封装及对象之间的继承关系。这样的操作看似复杂,但会极大地增加程序的复用性与可扩展性。同时通过对方法的封装,也可以使用户无需知道类的实现细节而可以直接调用,方便了用户的上手与使用。
1.10. Python 与 R 语法对照速查#
如果你熟悉 R 语言,可以通过以下的内容来对比 Python 与 R 语法的不同之处,以便于快速入门 Python 语法。
1.10.1. 打印#
print("Hello World!")
print("Hello World!")
1.10.2. 注释#
print("Hello Again")
# 这是一个注释
print("Hello Again")
# 这是一个注释
1.10.3. 运算符#
100 + 200 # 加法运算
200 - 100 # 减法运算
3 * 4 # 乘法运算
8 / 4 # 除法运算
2**3 # 指数运算
10 // 2 # 整除运算
10 % 3 # 取余运算
100 < 200 # 小于运算
200 > 100 # 大于运算
300 <= 200 # 小于等于运算
50 >= 200 # 大于等于运算
100 == 101 # 等于运算
100 != 101 # 不等于运算
True and True # 与运算
True or False # 或运算
not True # 非运算
100 + 200 # 加法运算
200 - 100 # 减法运算
3 * 4 # 乘法运算
8 / 4 # 除法运算
2**3 # 指数运算
10 %/% 2 # 整除运算
10 %% 3 # 取余运算
100 < 200 # 小于运算
200 > 100 # 大于运算
300 <= 200 # 小于等于运算
50 >= 200 # 大于等于运算
100 == 101 # 等于运算
100 != 101 # 不等于运算
TRUE & TRUE # 与运算
TRUE | FALSE # 或运算
!TRUE # 非运算
1.10.4. 变量赋值#
n_cats = 100
n_cats <- 100
1.10.5. 分支结构#
n_cats = 10
n_dogs = 5
if n_cats > n_dogs:
print("猫太多了!")
elif n_cats < n_dogs:
print("狗太多了!")
else:
print("恰好相等。")
n_cats <- 10
n_dogs <- 5
if (n_cats > n_dogs) {
print("猫太多了!")
} else if (n_cats < n_dogs){
print("狗太多了!")
} else {
print("恰好相等。")
}
1.10.6. 循环结构#
for-in 循环#
sum = 0
for i in range(0, 101):
sum = sum + i
print(sum)
sum <- 0
for (i in 0:100) {
sum = sum + i
}
print(sum)
while 循环#
x = 1
while True:
if x > 20:
break
if x % 3 == 0:
print(x)
x += 1
x <- 1
while (TRUE) {
if (x > 20) {
break
}
if (x %% 3 == 0) {
print(x)
}
x = x + 1
}
1.10.7. 函数#
def sum(start=0, end=100):
res = 0
for i in range(start, end + 1):
res = res + i
return res
a = sum()
sum <- function(start=0, end=100){
res = 0
for (i in start:end) {
res = res + i
}
return(res)
}
a = sum()
1.10.8. 列表#
animals = ["cat", "dog", "elephant", "dolphin"]
print(animals[0])
animals = c("cat", "dog", "elephant", "dolphin")
print(animals[1])
1.10.9. 字典#
animal_counts = {"cat": 20, "dog": 10, "elephant": 3}
print(animal_counts["cat"])
animal_counts = list(cat=20, dog=10, elephant=3)
print(animal_counts$cat)
1.11. 更多教程#
如果你想继续练习或更深入地学习 Python,可以参考:
Dusty, P. . (2018). Python 3 面向对象编程. 电子工业出版社.
David, B., & Brain, K. J. . (2015). Python Cookbook. 人民邮电出版社.