2. Python 数据科学入门#
Python 中提供了十分完善的数据科学生态,在本节中,我们将简单介绍 Python 中使用最为广泛的数据处理与分析包 NumPy 以及 pandas。其中 NumPy 主要用于数据计算,pandas 主要用于数据的筛选和拼接等数据处理操作。
在开始本节教程之前,推荐先阅读:Python 编程语言入门。
2.1. NumPy 入门教程#
NumPy 是 Python 中数据科学计算的一个基础包。它提供了多维数组对象以及用于数组快速运算的各种方法,例如数学运算、形状操作、基本统计分析、随机模拟等等。NumPy 几乎是整个 Python 数据科学生态的基础与核心,被广泛应用于包括机器学习在内的各个领域。
如果你想更全面的了解 NumPy 的使用方法以及实现原理等内容,可以参考:NumPy documentation。
2.1.1. 什么是数组#
NumPy 的核心为 ndarray 对象,它是一个 n 维数组,其中有序地存储着具有相同数据类型的数据,我们接下来将简称之为“数组”。
NumPy 的数组和 Python 中的 list 对象有一定的相似之处,但是有如下不同点:
数组的大小是固定的,无法动态扩增。
数组中的元素必须具有相同的数据类型。
数组支持更多的高级数学运算和其他操作。
以上的特点使得数组操作的执行效率更高、灵活性更强、代码更为简洁。
2.1.2. 导入 NumPy#
和导入其他第三方模块一样,我们使用 import 导入 NumPy。
import numpy as np
2.1.3. 创建数组#
NumPy 提供了许多方式来创建数组,接下来我们将讲解最为常用的几种。
从 list 创建数组#
使用 np.array() 方法可以将一个 list 类型的对象转为数组,这也是最常用的数组创建方法。
a = np.array([1, 2, 3, 4])
print(a) # 一维数组
[1 2 3 4]
小技巧
NumPy 数组与 R 中的 vector() 类似。即 a = np.array([1, 2, 3, 4]) 类似于 R 中 a = c(1, 2, 3, 4)。
b = np.array([[5, 6], [7, 8]])
print(b) # 二维数组
[[5 6]
[7 8]]
备注
二维数组即矩阵。
创建指定范围的数组#
使用 np.arange() 或者 np.linspace() 可以创建指定范围的数组,在构建群体模型模拟数据时十分常用。可以通过以下几个例子观察两个方法之间的差异,你可以阅读它们的文档字符串获取更多信息。
# arange 指定的是步长,且为前闭后开区间
a = np.arange(0, 30, 5)
print(a)
[ 0 5 10 15 20 25]
b = np.arange(0, 2, 0.3)
print(b)
[0. 0.3 0.6 0.9 1.2 1.5 1.8]
# linspace 指定的是个数
c = np.linspace(0, 30, 5)
print(c)
[ 0. 7.5 15. 22.5 30. ]
小技巧
如果你熟悉 R 语言的话,np.arange() 与 R 中的 seq() 有一定的相似之处。
创建具有相同数据的数组#
使用 np.zeros()、np.ones()、np.full() 可以快速创建指定形状的具有相同数据的数组。
# 创建一个长度为 5,数组值均为 0 的数组
a = np.zeros(5)
print(a)
[0. 0. 0. 0. 0.]
# 创建一个长度为 10,数组值均为 1 的数组
b = np.ones(10)
print(b)
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
# 创建一个大小为 3*3,数组值均为 3.14 的二维数组
c = np.full((3, 3), 3.14)
print(c)
[[3.14 3.14 3.14]
[3.14 3.14 3.14]
[3.14 3.14 3.14]]
小技巧
同样的,如果你熟悉 R 语言的话,这些函数与 R 中的 rep() 类似。
创建随机数数组#
使用 np.random 下的函数可以快速创建含有随机数的数组。
# 设置随机种
np.random.seed(1234)
# 创建一个由在 [0~1) 内均匀分布的随机数组成的长度为 5 的数组
a = np.random.random(5)
print(a)
[0.19151945 0.62210877 0.43772774 0.78535858 0.77997581]
# 创建一个由符合标准正态分布的随机数组成的长度为 10 的数组
b = np.random.normal(size=10)
print(b)
## 创建一个符合均值为 10,标准差为 3 的正态分布的长度为 10 的数组
c = np.random.normal(loc=10, scale=3, size=10)
print(c)
[-0.94029827 -0.95658428 -0.33060682 0.87412791 2.00254961 0.01086208
-0.86924706 1.4249841 0.1458091 2.89409095]
[ 9.08721945 12.58498301 7.93021999 10.56249211 11.81292623 9.45095733
6.6204926 14.97661852 8.01867576 13.12325791]
# 创建一个由在 [0~100) 内均匀分布的随机整数组成的长度为 10 的数组
d = np.random.randint(0, 100, 10)
print(d)
[71 60 46 28 81 87 13 96 12 69]
小技巧
这些函数也和 R 中的 runif()、rnorm() 有共通之处。
2.1.4. 数组的运算#
基本算术与逻辑运算#
在 NumPy 中,支持对数组的基本算术运算和逻辑运算,例如加减乘除、大于小于逻辑比较等。这些运算是逐元素的,可以观察下方的例子:
a = np.array([1, 2, 3, 4])
print("a + 2:", a + 2)
print("a * 1.5:", a * 1.5)
print("a < 3:", a < 3)
a + 2: [3 4 5 6]
a * 1.5: [1.5 3. 4.5 6. ]
a < 3: [ True True False False]
除了与数字进行运算外,数组和数组之间也可以进行运算,参考下方的例子:
a = np.array([1, 2, 3, 4])
b = np.full(4, 4)
print("a + b:", a + b)
print("a * b:", a * b)
a + b: [5 6 7 8]
a * b: [ 4 8 12 16]
思考一个问题:如果上述例子中的 a 与 b 不等长的话,对两者进行运算会发生什么?
a = np.array([1, 2, 3, 4])
b = np.array([4])
print("a + b:", a + b)
a + b: [5 6 7 8]
观察上面的例子,我们可以发现即使两个数组不等长也可以执行运算——数组 a 的每个元素都被加上了 4。
这一运算能实现的原因是因为 NumPy 会对较短的数组进行广播(broadcast),其原理可以参考 图 2.149:
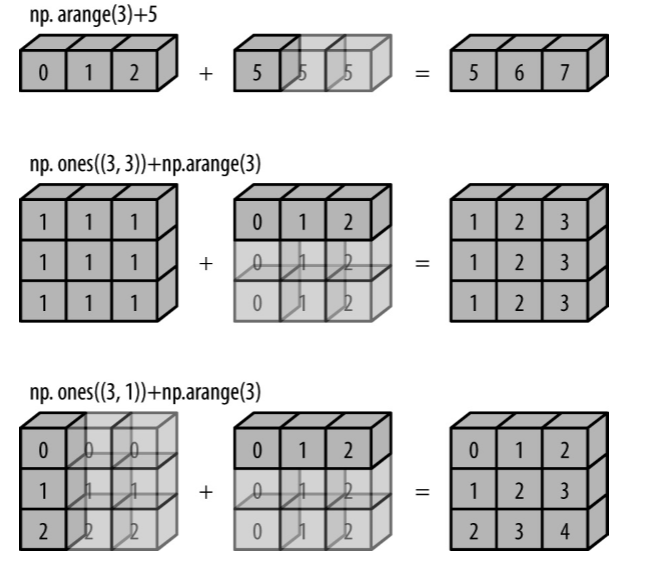
图 2.149 广播机制原理示意图#
数学函数#
NumPy 也支持对数组进行一些常用的数学函数运算,例如 sin、cos 等。这些函数被称为 “universal functions”(ufunc)。这些函数也是逐元素操作数组的。
a = np.array([1, 2, 3, 4])
print("a:", a)
print("sin(a):", np.sin(a))
print("cos(a):", np.cos(a))
print("a^0.5:", np.sqrt(a))
print("3^a:", np.power(3, a))
print("e^a:", np.exp(a))
print("ln(a):", np.log(a))
print("log10(a):", np.log10(a))
a: [1 2 3 4]
sin(a): [ 0.84147098 0.90929743 0.14112001 -0.7568025 ]
cos(a): [ 0.54030231 -0.41614684 -0.9899925 -0.65364362]
a^0.5: [1. 1.41421356 1.73205081 2. ]
3^a: [ 3 9 27 81]
e^a: [ 2.71828183 7.3890561 20.08553692 54.59815003]
ln(a): [0. 0.69314718 1.09861229 1.38629436]
log10(a): [0. 0.30103 0.47712125 0.60205999]
备注
和手动撰写循环语句进行计算相比,这些函数的运行效率更高。
统计分析#
NumPy 也支持对数组内的元素进行一些基础的统计分析,例如求极值、求均值等。
a = np.arange(0, 11)
print("a:", a)
print("求和:", np.sum(a))
print("均值:", np.mean(a))
print("标准差:", np.std(a))
print("方差:", np.var(a))
print("最大值:", np.max(a))
print("最小值:", np.min(a))
print("中位数:", np.median(a))
print("第 90 分位数:", np.percentile(a, 90))
a: [ 0 1 2 3 4 5 6 7 8 9 10]
求和: 55
均值: 5.0
标准差: 3.1622776601683795
方差: 10.0
最大值: 10
最小值: 0
中位数: 5.0
第 90 分位数: 9.0
小技巧
这些统计分析功能也以数组的类方法的形式实现了。例如需要计算数组 a 的均值,你可以直接使用 a.mean(),其结果和 np.mean(a) 是一致的。
2.1.5. 数组的取值#
和 Python 原生的 list 对象类似,NumPy 数组也支持使用索引值取值。
a = np.arange(0, 10)
print("a:", a)
print("a[1]:", a[1])
print("a[-2]:", a[-2])
print("a[5:]:", a[5:])
print("a[:3]:", a[:3])
print("a[0:4]:", a[0:3])
a: [0 1 2 3 4 5 6 7 8 9]
a[1]: 1
a[-2]: 8
a[5:]: [5 6 7 8 9]
a[:3]: [0 1 2]
a[0:4]: [0 1 2]
除了使用单个整数作为索引值进行取值,也可以使用整数列表来对数组进行取值:
a = np.arange(0, 10)
print("a:", a)
print("索引值为 0, 2 与 5 的元素:", a[[0, 2, 5]])
a: [0 1 2 3 4 5 6 7 8 9]
索引值为 0, 2 与 5 的元素: [0 2 5]
除此之外,我们也可以使用逻辑表达式(本质上是传入了一个布尔值数组)来进行取值,这样的操作在数据筛选时十分常用。
a = np.arange(0, 10)
print("a:", a)
print("小于 5 的元素是:", a[a < 5])
print("是偶数的元素是:", a[a % 2 == 0])
a: [0 1 2 3 4 5 6 7 8 9]
小于 5 的元素是: [0 1 2 3 4]
是偶数的元素是: [0 2 4 6 8]
2.1.6. 数组的拼接和切分#
数组的拼接#
在 NumPy 可以灵活地对数组进行拼接,这些操作可以有助于我们快速构建大型数据。
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.concatenate([a, b]) # 拼接数组
print(c)
[1 2 3 4 5 6]
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.vstack([a, b]) # 纵向拼接一维数组
print(c)
[[1 2 3]
[4 5 6]]
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.hstack([a, b]) # 横向拼接一维数组
print(c)
[1 2 3 4 5 6]
在二维数组中,np.vstack() 与 np.hstack() 的差异更为明显:
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
c = np.vstack([a, b]) # 纵向拼接二维数组
print(c)
[[1 2]
[3 4]
[5 6]
[7 8]]
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
c = np.hstack([a, b]) # 横向拼接二维数组
print(c)
[[1 2 5 6]
[3 4 7 8]]
小技巧
这些拼接方法和 R 中的 cbind() 和 rbind() 也有一定的相同点。
数组的切分#
与拼接操作类似,我们可以使用 np.split()、np.vsplit() 和 np.hsplit() 来切分数组。
需要注意的是,使用这些函数时需要传入欲切分的个数或切分点的位置。他们的差异可以观察下方的例子:
a = np.arange(0, 10)
# 若传入一个整数,则其将被视为欲切分的个数
b = np.split(a, 5) # 切分为五个数组
print(b)
# 若传入一个一维数组或列表,则其将被视为切分点的位置
c = np.split(a, [5]) # 在索引值为 5 的位置切分数组
print(c)
[array([0, 1]), array([2, 3]), array([4, 5]), array([6, 7]), array([8, 9])]
[array([0, 1, 2, 3, 4]), array([5, 6, 7, 8, 9])]
以下是一些二维数组使用 np.vsplit() 和 np.hsplit() 的例子:
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
b = np.vsplit(a, [1]) # 纵向切分
print(b)
[array([[1, 2, 3, 4]]), array([[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])]
a = np.array([[1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12]])
b = np.hsplit(a, [2, 4]) # 横向切分
print(b)
[array([[1, 2],
[7, 8]]), array([[ 3, 4],
[ 9, 10]]), array([[ 5, 6],
[11, 12]])]
2.2. polars 入门教程#
与 NumPy 类似,polars 也是 Python 数据科学生态中的核心之一。其提供的数据结构可以使我们更灵活地完成数据导入导出、数据清理、缺失值处理、数据分析等工作。
在阅读下文前,推荐先阅读本节中的 NumPy 入门教程。
若你想更深入地了解 polars,可以参考:polars documentation。
2.2.1. 导入 polars#
类似于导入 NumPy,我们使用 import 导入 polars。推荐同时导入 NumPy 以便于进行后续数据集的创建操作。
import numpy as np
import polars as pl
2.2.2. Series 和 DataFrame#
polars 的基础数据结构有两种,分别为 DataFrame 和 Series。
DataFrame 与我们在 Excel 中常用的表格类似:它是一个二维数据集,由行与列组成,且同时拥有列名与行名。在下文中,我们将简称 DataFrame 对象为“数据集”。
df = pl.DataFrame(
{
"Name": [
"Marlin",
"Dory",
"Nemo",
],
"Length": [20, 35, 18],
"Width": [6.5, 9.8, 5.8],
}
)
df
| Name | Length | Width |
|---|---|---|
| str | i64 | f64 |
| "Marlin" | 20 | 6.5 |
| "Dory" | 35 | 9.8 |
| "Nemo" | 18 | 5.8 |
DataFrame 的每一列都是一个 Series。可以将 Series 理解为一个带标签的一维列表。
df["Name"] # 可以使用 [] 取出一列
| Name |
|---|
| str |
| "Marlin" |
| "Dory" |
| "Nemo" |
print("polars DataFrame 的每一列的类型是:")
type(df["Name"])
polars DataFrame 的每一列的类型是:
polars.series.series.Series
小技巧
DataFrame 与 R 语言中的 data.frame 类似。此外,下文中的许多函数也有在 R 语言中对应或相似的版本。
2.2.3. 创建数据集#
我们可以用 list,ndarray 或者 dict 对象来创建一个数据集:
df1 = pl.DataFrame([[28.5, 30, 31.1, 26.8], ["Female", "Male", "Female", "Male"]], schema=["Score", "Sex"])
df1
| Score | Sex |
|---|---|
| f64 | str |
| 28.5 | "Female" |
| 30.0 | "Male" |
| 31.1 | "Female" |
| 26.8 | "Male" |
df2 = pl.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
df2
| column_0 | column_1 | column_2 |
|---|---|---|
| i32 | i32 | i32 |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
df3 = pl.DataFrame(
{"ID": [1, 2, 3, 4], "Age": pl.Series([20, 19, 24, 36]), "Score": np.array([96, 97, 88, 90]), "Country": "China"}
)
df3
| ID | Age | Score | Country |
|---|---|---|---|
| i64 | i64 | i32 | str |
| 1 | 20 | 96 | "China" |
| 2 | 19 | 97 | "China" |
| 3 | 24 | 88 | "China" |
| 4 | 36 | 90 | "China" |
2.2.4. 数据集检视#
首先,我们可以直接使用 print() 来查看完整的数据集:
df = pl.DataFrame(
{
"ID": [1, 2, 3, 4, 5, 6, 7, 8],
"Age": [20, 19, 24, 36, 18, 21, 24, 25],
"Score": [96, 97, 88, 90, 76, 89, 91, 85],
}
)
df
| ID | Age | Score |
|---|---|---|
| i64 | i64 | i64 |
| 1 | 20 | 96 |
| 2 | 19 | 97 |
| 3 | 24 | 88 |
| 4 | 36 | 90 |
| 5 | 18 | 76 |
| 6 | 21 | 89 |
| 7 | 24 | 91 |
| 8 | 25 | 85 |
在实际场景中,药物数据集一般都较为庞大,此时我们可以使用 DataFrame.head() 或者 DataFrame.tail() 来检视数据集开头或末尾的几行:
df.head(5)
| ID | Age | Score |
|---|---|---|
| i64 | i64 | i64 |
| 1 | 20 | 96 |
| 2 | 19 | 97 |
| 3 | 24 | 88 |
| 4 | 36 | 90 |
| 5 | 18 | 76 |
df.tail(3)
| ID | Age | Score |
|---|---|---|
| i64 | i64 | i64 |
| 6 | 21 | 89 |
| 7 | 24 | 91 |
| 8 | 25 | 85 |
对于大型数据集,使用 DataFrame.describe() 方法获取数据集的描述性统计摘要也是十分实用的:
df.describe()
| statistic | ID | Age | Score |
|---|---|---|---|
| str | f64 | f64 | f64 |
| "count" | 8.0 | 8.0 | 8.0 |
| "null_count" | 0.0 | 0.0 | 0.0 |
| "mean" | 4.5 | 23.375 | 89.0 |
| "std" | 2.44949 | 5.705574 | 6.590036 |
| "min" | 1.0 | 18.0 | 76.0 |
| "25%" | 3.0 | 20.0 | 88.0 |
| "50%" | 5.0 | 24.0 | 90.0 |
| "75%" | 6.0 | 24.0 | 91.0 |
| "max" | 8.0 | 36.0 | 97.0 |
可以使用 DataFrame.columns 属性来查看数据集的列名:
df.columns
['ID', 'Age', 'Score']
2.2.5. 数据集排序#
使用 DataFrame.sort 就可以根据数据的大小对数据集进行排序:
df = pl.DataFrame(
{
"ID": [1, 2, 3, 4],
"Age": [20, 19, 24, 36],
"Score": [96, 97, 88, 90],
"Name": ["Marlin", "Dory", "Nemo", "Bruce"],
}
)
df
| ID | Age | Score | Name |
|---|---|---|---|
| i64 | i64 | i64 | str |
| 1 | 20 | 96 | "Marlin" |
| 2 | 19 | 97 | "Dory" |
| 3 | 24 | 88 | "Nemo" |
| 4 | 36 | 90 | "Bruce" |
df.sort("Name")
| ID | Age | Score | Name |
|---|---|---|---|
| i64 | i64 | i64 | str |
| 4 | 36 | 90 | "Bruce" |
| 2 | 19 | 97 | "Dory" |
| 1 | 20 | 96 | "Marlin" |
| 3 | 24 | 88 | "Nemo" |
df.sort("Name", descending=True) # 递减排序
| ID | Age | Score | Name |
|---|---|---|---|
| i64 | i64 | i64 | str |
| 3 | 24 | 88 | "Nemo" |
| 1 | 20 | 96 | "Marlin" |
| 2 | 19 | 97 | "Dory" |
| 4 | 36 | 90 | "Bruce" |
df.sort(by=["Score"]) # 以 "Score" 列数据的大小递增排序
| ID | Age | Score | Name |
|---|---|---|---|
| i64 | i64 | i64 | str |
| 3 | 24 | 88 | "Nemo" |
| 4 | 36 | 90 | "Bruce" |
| 1 | 20 | 96 | "Marlin" |
| 2 | 19 | 97 | "Dory" |
2.2.6. 缺失值处理#
在处理药物数据时,时常会出现缺失值,polars 也提供了丰富的检查缺失值(DataFrame.is_null())、删除缺失值(DataFrame.drop_nulls())、替换缺失值(DataFrame.fill_null())的方法。
df = pl.DataFrame({"Time": [0, 2, 4, 8, 12, 16], "Conc": [0.0, 0.9, 2.4, None, 0.7, None]})
df
| Time | Conc |
|---|---|
| i64 | f64 |
| 0 | 0.0 |
| 2 | 0.9 |
| 4 | 2.4 |
| 8 | null |
| 12 | 0.7 |
| 16 | null |
df.select(pl.col("Conc").is_null().alias("Conc_is_missing")) # 判断数据是否为缺失值
| Conc_is_missing |
|---|
| bool |
| false |
| false |
| false |
| true |
| false |
| true |
df.drop_nulls() # 丢弃含缺失值的行
| Time | Conc |
|---|---|
| i64 | f64 |
| 0 | 0.0 |
| 2 | 0.9 |
| 4 | 2.4 |
| 12 | 0.7 |
lloq = 0.05
df.fill_null(lloq / 2) # 替换缺失值
| Time | Conc |
|---|---|
| f64 | f64 |
| 0.0 | 0.0 |
| 2.0 | 0.9 |
| 4.0 | 2.4 |
| 8.0 | 0.025 |
| 12.0 | 0.7 |
| 16.0 | 0.025 |
2.2.7. 数据集的运算#
与 NumPy 数组一样,polars 的数据集也支持基础的算数运算、逻辑运算和基本统计分析功能。
基本算术与逻辑运算#
df = pl.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]})
df
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 0 | 3 | 6 |
| 1 | 4 | 7 |
| 2 | 5 | 8 |
df + 2
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 2 | 5 | 8 |
| 3 | 6 | 9 |
| 4 | 7 | 10 |
df * 4
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 0 | 12 | 24 |
| 4 | 16 | 28 |
| 8 | 20 | 32 |
df < 5
| A | B | C |
|---|---|---|
| bool | bool | bool |
| true | true | false |
| true | true | false |
| true | false | false |
NumPy 中的 数学函数(ufunc)也可以作用于数据集:
np.sin(df)
array([[ 0. , 0.14112001, -0.2794155 ],
[ 0.84147098, -0.7568025 , 0.6569866 ],
[ 0.90929743, -0.95892427, 0.98935825]])
np.exp(df)
array([[1.00000000e+00, 2.00855369e+01, 4.03428793e+02],
[2.71828183e+00, 5.45981500e+01, 1.09663316e+03],
[7.38905610e+00, 1.48413159e+02, 2.98095799e+03]])
数据集与数据集之间也可以进行运算:
df1 = pl.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]})
df1
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 0 | 3 | 6 |
| 1 | 4 | 7 |
| 2 | 5 | 8 |
df2 = pl.DataFrame({"A": [9, 10, 11], "B": [12, 13, 14], "C": [6, 7, 8]})
df2
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 9 | 12 | 6 |
| 10 | 13 | 7 |
| 11 | 14 | 8 |
df1 + df2
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 9 | 15 | 12 |
| 11 | 17 | 14 |
| 13 | 19 | 16 |
统计分析#
pandas 数据集也支持 NumPy 中的 统计分析函数:
df = pl.DataFrame({"A": [0, 1, 2, 3], "B": [4, 5, 6, 7], "C": [8, 9, 10, 11]})
df
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 0 | 4 | 8 |
| 1 | 5 | 9 |
| 2 | 6 | 10 |
| 3 | 7 | 11 |
print("各列所有数据总和:")
df.sum()
各列所有数据总和:
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 6 | 22 | 38 |
print("各列数据均值:")
df.mean()
各列数据均值:
| A | B | C |
|---|---|---|
| f64 | f64 | f64 |
| 1.5 | 5.5 | 9.5 |
2.2.8. 数据集的取值#
一般来说,我们可以使用 [] 完成对数据集的取值操作。
使用 [列名] 可以取出某列,使用 [行号:行号] 可以取出某些行:
df = pl.DataFrame({"ID": [1, 1, 1, 2, 2, 2], "Time": [0, 2, 4, 0, 2, 4], "Conc": [0.0, 1.4, 6.7, 0.05, 1.2, 7.8]})
df
| ID | Time | Conc |
|---|---|---|
| i64 | i64 | f64 |
| 1 | 0 | 0.0 |
| 1 | 2 | 1.4 |
| 1 | 4 | 6.7 |
| 2 | 0 | 0.05 |
| 2 | 2 | 1.2 |
| 2 | 4 | 7.8 |
print("浓度列数据:")
df["Conc"]
浓度列数据:
| Conc |
|---|
| f64 |
| 0.0 |
| 1.4 |
| 6.7 |
| 0.05 |
| 1.2 |
| 7.8 |
print("第2-3行数据:")
df[1:3]
第2-3行数据:
| ID | Time | Conc |
|---|---|---|
| i64 | i64 | f64 |
| 1 | 2 | 1.4 |
| 1 | 4 | 6.7 |
不过对于复杂的筛选场景,简单的 [] 取值似乎有些捉襟见肘。这时候我们就需要使用 polars 强大的 select/filter/col/selector 的表达式组合来达成我们的筛选目的。
列选择 select#
对于 polars 数据集,我们可以使用 select 函数来选择列并对列的值进行变换。
import polars.selectors as selectors
df = pl.DataFrame(
{
"Province": ["California", "Texas", "New York", "Florida", "Illinois"],
"Area": [423967, 695662, 141297, 170312, 149995],
"Population": [38332521, 26448193, 19651127, 19552860, 12882135],
},
)
df
| Province | Area | Population |
|---|---|---|
| str | i64 | i64 |
| "California" | 423967 | 38332521 |
| "Texas" | 695662 | 26448193 |
| "New York" | 141297 | 19651127 |
| "Florida" | 170312 | 19552860 |
| "Illinois" | 149995 | 12882135 |
# 全选
df.select(pl.all())
| Province | Area | Population |
|---|---|---|
| str | i64 | i64 |
| "California" | 423967 | 38332521 |
| "Texas" | 695662 | 26448193 |
| "New York" | 141297 | 19651127 |
| "Florida" | 170312 | 19552860 |
| "Illinois" | 149995 | 12882135 |
# 数值列
df.select(selectors.numeric())
| Area | Population |
|---|---|
| i64 | i64 |
| 423967 | 38332521 |
| 695662 | 26448193 |
| 141297 | 19651127 |
| 170312 | 19552860 |
| 149995 | 12882135 |
# 以 "P" 开头的列
df.select(selectors.starts_with("P"))
| Province | Population |
|---|---|
| str | i64 |
| "California" | 38332521 |
| "Texas" | 26448193 |
| "New York" | 19651127 |
| "Florida" | 19552860 |
| "Illinois" | 12882135 |
行选择 filter#
选择行的行为和选择列类似,polars 提供了 filter 该方法来实现这个功能。
# 选择人口数量大于 2e7 的数据
df.filter(pl.col("Population") > 2e7)
| Province | Area | Population |
|---|---|---|
| str | i64 | i64 |
| "California" | 423967 | 38332521 |
| "Texas" | 695662 | 26448193 |
# 选择人均面积大于 0.01 的数据
df.filter((pl.col("Area") / pl.col("Population")) > 0.01)
| Province | Area | Population |
|---|---|---|
| str | i64 | i64 |
| "California" | 423967 | 38332521 |
| "Texas" | 695662 | 26448193 |
| "Illinois" | 149995 | 12882135 |
2.2.9. CSV 文件的导入和导出#
使用 pl.read_csv() 和 pl.write_csv() 可以实现本地 CSV 文件的导入与导出:
import tempfile
import pathlib
save_to = pathlib.Path(tempfile.gettempdir()) / "example.csv"
df = pl.DataFrame(
{"Name": ["Bob", "Jake", "Lisa", "Sue"], "Department": ["Accounting", "Engineering", "Engineering", "HR"]}
)
df.write_csv(save_to)
pl.read_csv(save_to, infer_schema_length=None)
| Name | Department |
|---|---|
| str | str |
| "Bob" | "Accounting" |
| "Jake" | "Engineering" |
| "Lisa" | "Engineering" |
| "Sue" | "HR" |