4. 教程: 数据处理与可视化#
在本节中,我们将学习如何进行数据切分,并通过箱型图的方式对切分后的数据进行可视化。
在开始本节教程前,推荐掌握在软件中新建分析、载入仿例与运行分析等操作,可参考:开始使用 Maspectra。
4.1. 为什么要数据处理和可视化?#
在临床数据分析中,我们首先接触到的就是数据。而这些临床前或临床后的数据,往往数据量较大且来源较为复杂(例如由不同试验人员或不同设备记录得来的数据)。因此在真正开始分析之前,我们需要对数据进行处理(也被称为数据清洁),以获取我们真正关注的或有具有潜在挖掘价值的数据。
对于处理后的数据,我们常通过图形来对数据进行可视化,以探索和发掘数据中的信息。例如我们可以通过箱型图和直方图来确定数据的分布和发现离群值,我们也可以使用折线图来观察血药浓度和时间的关系(图 4.1)。
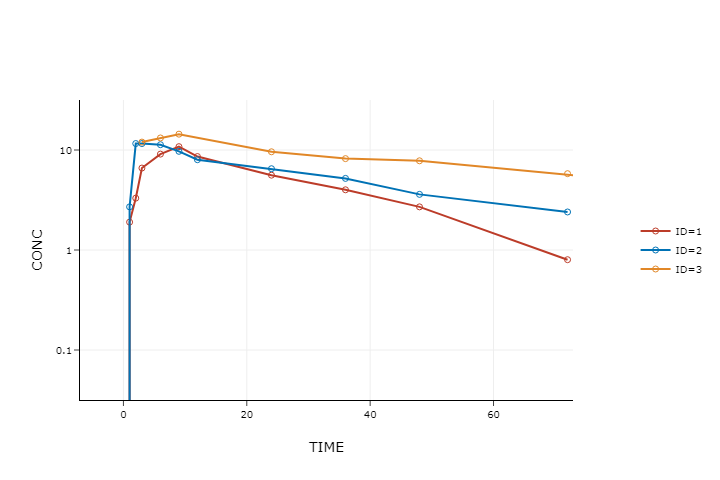
图 4.1 血药浓度-时间折线图#
4.2. 数据切分#
进入软件后,我们在新建分析页中选择 “数据处理 > 数据切分”,来创建数据切分。同样的,我们也可以通过左侧侧边栏 “功能” 选项中找到 “数据处理 > 数据切分” 来创建(图 4.2)。
图 4.2 “数据切分” 选项示意图#
新建数据处理后,我们可以点击数据处理标签页右上角的 “载入仿例”
 按钮来载入示例数据。示例数据中的三列分别代表了:试验组别、受试者编号和受试者体重(图 4.3)。
按钮来载入示例数据。示例数据中的三列分别代表了:试验组别、受试者编号和受试者体重(图 4.3)。在开始运行前,我们先简单介绍一下我们的数据表格形式。在表头中,包含了数据列列名(下方的粗体字)及其映射关系(上方的小号文本)。映射关系表明了这一数据列将被映射为何种类型——决定了其身份或功能。例如,在当前的示例数据中,
GROUP列被映射为了索引,意为我们将视GROUP列为数据切分的索引,将依据其中的数据值水平进行切分。而被映射为保留的列,则说明其在数据切分后将被保留在切分结果内。
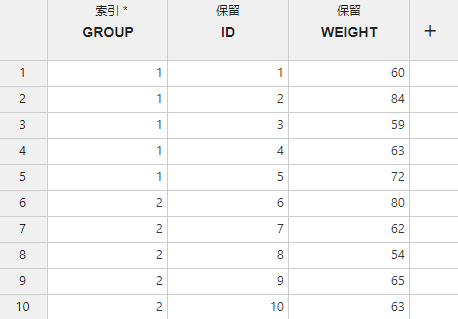
图 4.3 数据表格示意图#
现在点击右上角
 按钮或底部 “运行” 按钮,我们可以得到依据
按钮或底部 “运行” 按钮,我们可以得到依据 GROUP值切分而来的三个切分后数据集。例如点击左侧工作流下 “数据切分” 的 “结果” 中的 “GROUP=1”,我们就可以检查其中一组的切分结果(图 4.4)。
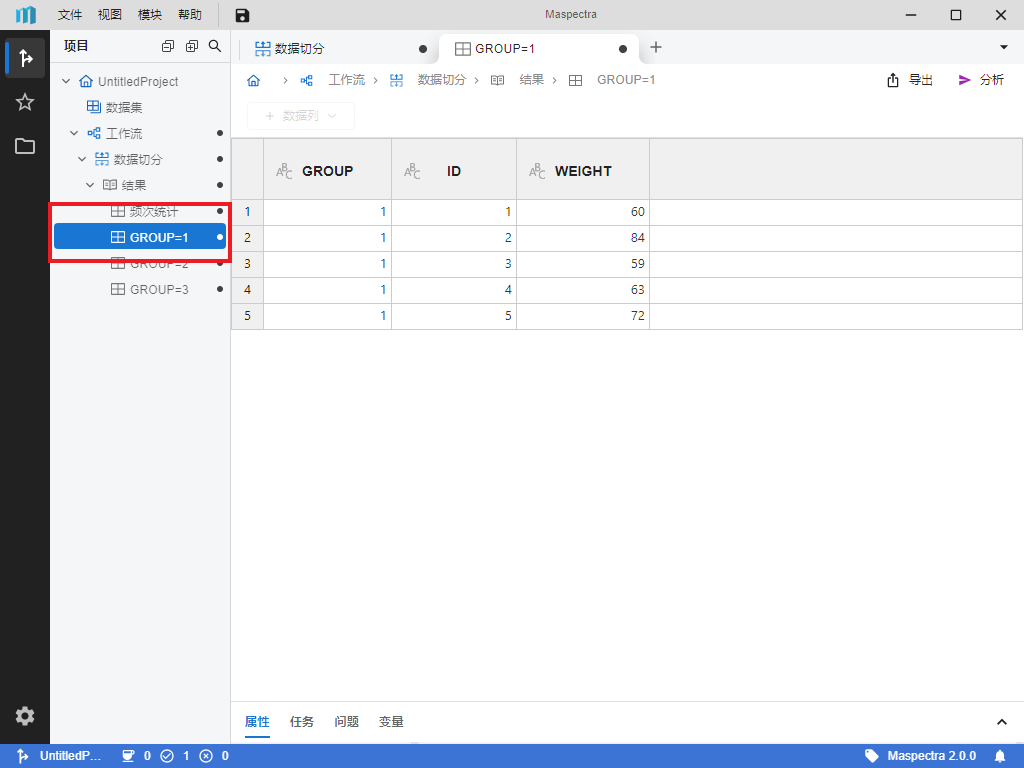
图 4.4 数据切分结果示意图#
我们可以点击右上角的
 按钮来将这个结果数据集用于下一步的分析或处理。在下文中,我们将对某个试验组别绘制一张箱型图以检视受试者的体重分布情况,所以此次我们点击在 “GROUP=1” 数据集右上角的 按钮(图 4.5),在弹出的窗口中选择 “图法评价 > 箱型图” (图 4.6),以检视
按钮来将这个结果数据集用于下一步的分析或处理。在下文中,我们将对某个试验组别绘制一张箱型图以检视受试者的体重分布情况,所以此次我们点击在 “GROUP=1” 数据集右上角的 按钮(图 4.5),在弹出的窗口中选择 “图法评价 > 箱型图” (图 4.6),以检视 GROUP=1数据的受试者体重分布情况。
图 4.5 发送结果数据表按钮位置示意图#
图 4.6 “箱型图” 选项示意图#
4.3. 绘制箱型图#
在上文中,我们将切分后的数据集发送至了箱型图中。此时我们在箱型图标签页中可以发现界面变为了 “链接数据” 模式,表明了绘制箱型图所使用的数据正是上文中切分后的数据集。在 “链接数据” 模式中,可通过拖拽数据列的方法完成映射关系设定。由于我们需要对受试者体重进行检视,所以我们拖拽 “WEIGHT” 进入 “Y 轴” 框内(图 4.7),完成箱型图的映射。
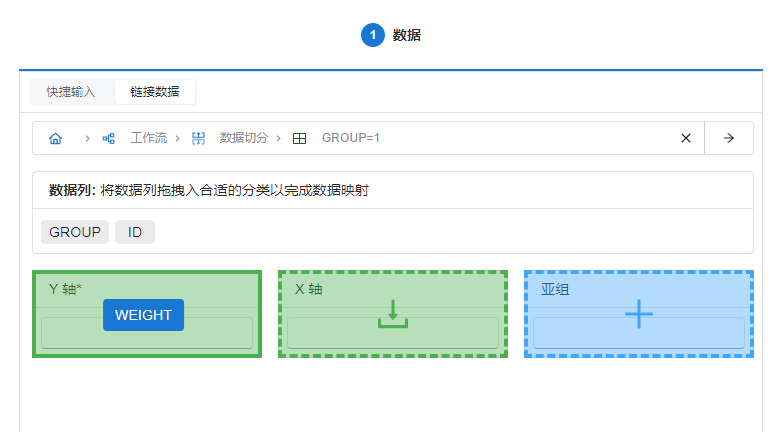
图 4.7 “链接数据” 模式数据列拖拽操作示意图#
完成必选列(即带星号
*的列)的映射后,点击右上角 按钮或底部 “运行” 按钮,即可绘制箱型图,结果如 图 4.8 所示。
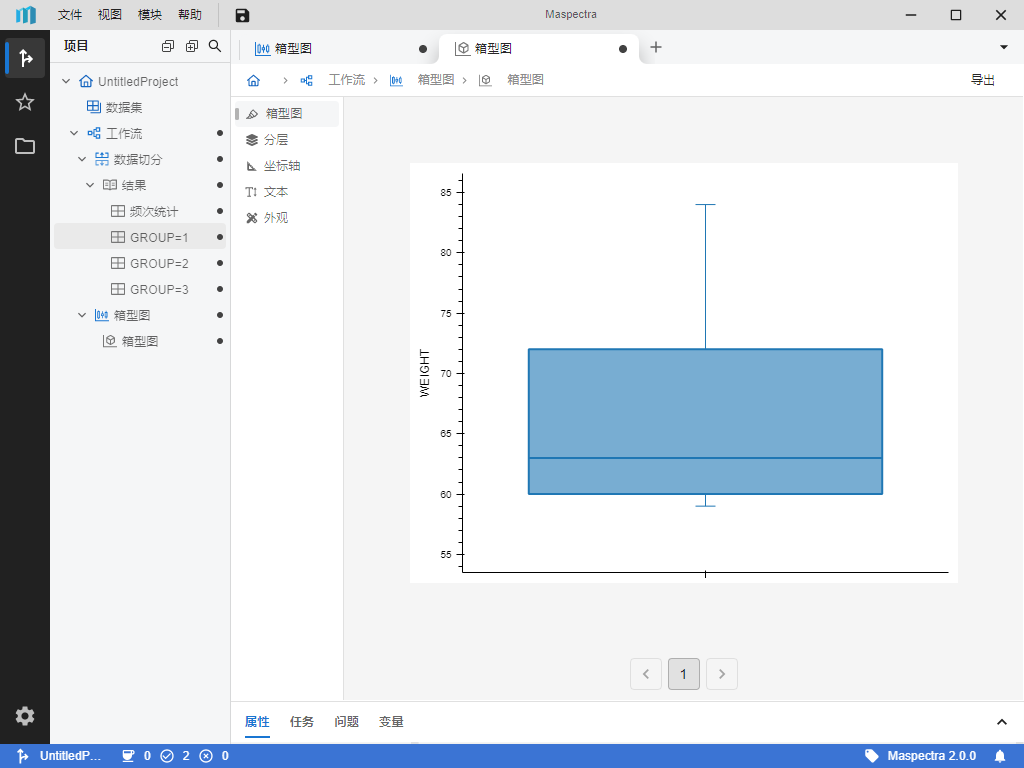
图 4.8 箱型图绘制完成示意图#
绘制完成的图形可以保存至本地。点击右上角的
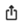 导出按钮,即可保存至指定路径(图 4.9)。
导出按钮,即可保存至指定路径(图 4.9)。
图 4.9 保存图形示意图#
备注
我们采用 Python 第三方工具 Bokeh 来生成可交互式的图形。关于 Bokeh 图形的交互方法及更多操作,可详见:Bokeh
当然,我们也可以调整图形的样式。接下来我们将尝试修改一下箱型图的箱体颜色。我们内置了丰富的配色方案,例如我们想要一个新英格兰期刊(The New England Journal of Medicine)配色的箱体:点击图形标签页左侧侧边栏中 “分层 > 标志样式 > 配色主题 > NEJM” 即可(图 4.10)。
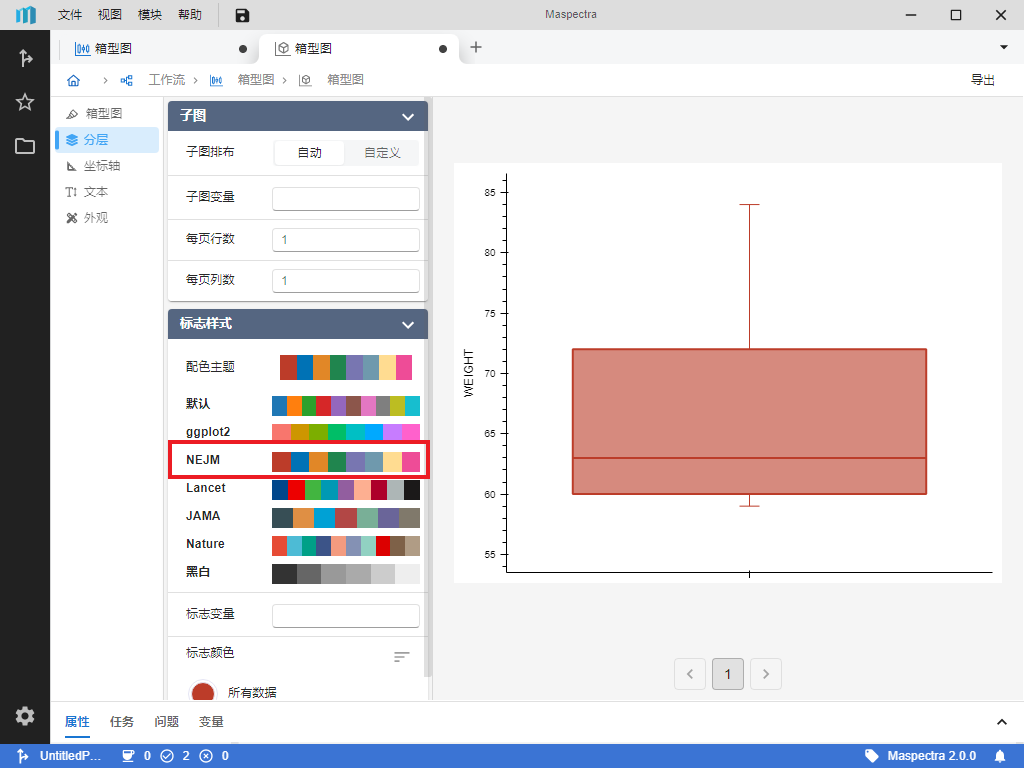
图 4.10 更换配色主题示意图#