2. 数据处理#
在本节中,我们将介绍各个数据处理功能的使用方法。合理地使用这些功能可以帮助我们整理原始数据以用于进一步的分析。
当前版本中支持的相关功能包括:
2.1. 数据切分#
使用此功能可依据索引将数据切分为若干个新数据。例如对于 PK-PD 数据集,可将其切分为 PK 与 PD 数据以便于分别分析。
2.1.1. 数据映射关系#
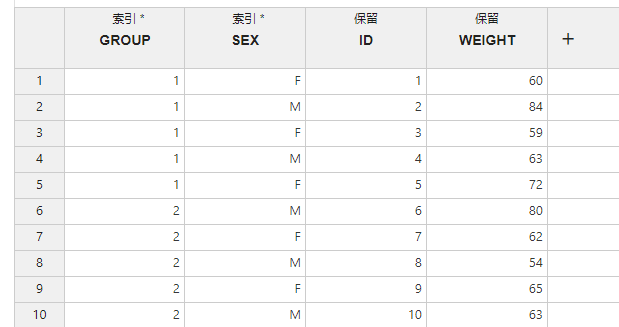
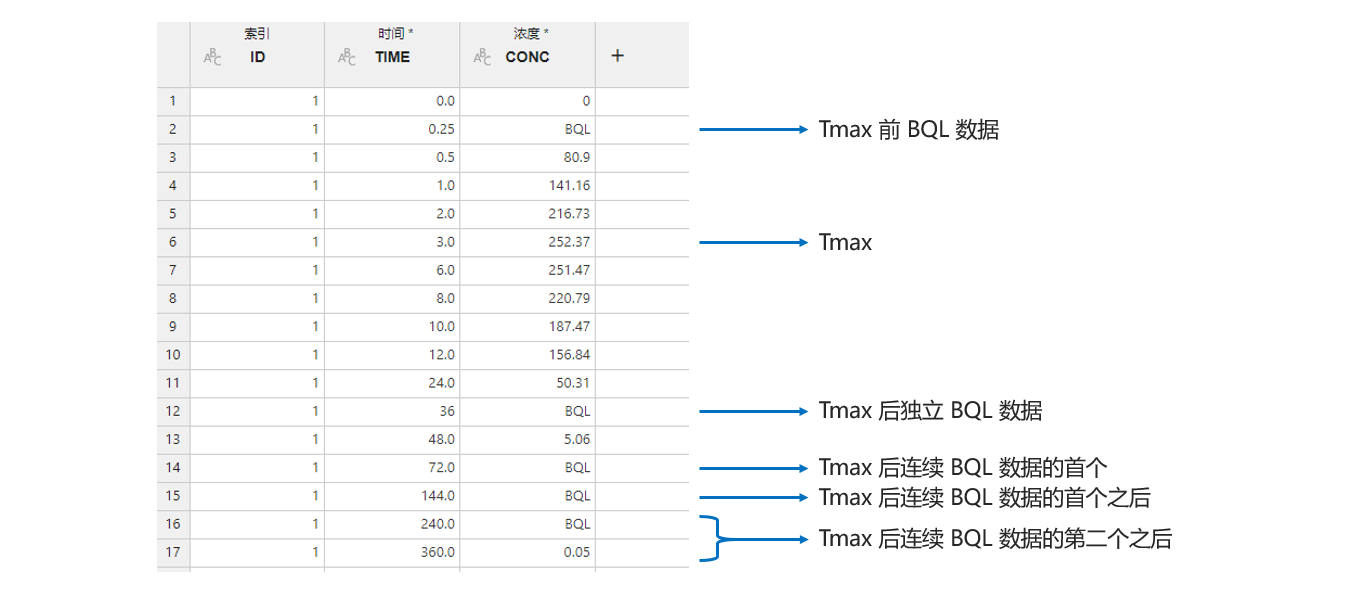
图 2.44 数据切分映射关系示意图#
索引 (必选项,多选):切分索引。将依据被映射为此项的数据列中的数据值水平对原始数据进行切分,即拥有同一索引值的数据行将被切分至同一个子数据集中。
保留 (可选项,多选):需要保留的数据列。映射为此项的数据将在切分后的子数据集内被保留,否则将被丢弃。
2.1.2. 结果#
频次统计#
包含各索引值排列组合出现频次的表格(图 2.45)。
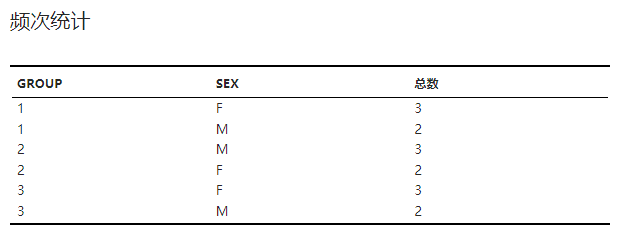
图 2.45 数据切分频次统计表格示意图#
子数据集#
根据索引值切分而来的数据集,以 索引列名=索引值 的形式命名(图 2.46)。
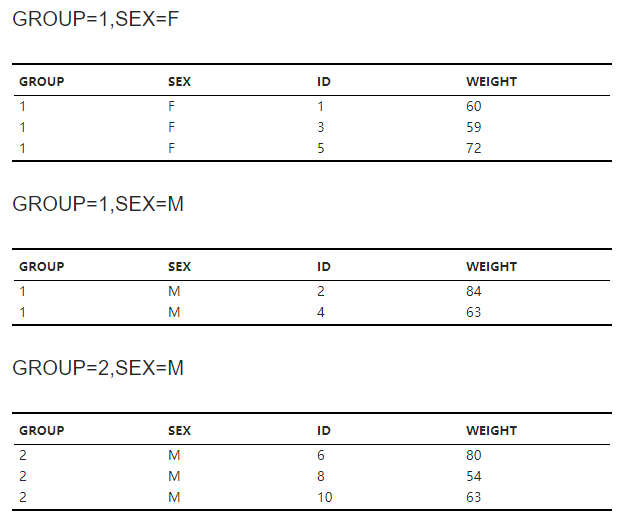
图 2.46 数据切分子数据集示意图#
重要
出于性能上的考虑,目前仅支持对切分后将生成 30 个子数据集以内的数据进行数据切分。
2.2. 长表转置#
可依据索引将长表转置为宽表。例如通过此功能可以直观地观察某参数估计结果在不同受试者间的变化情况。
2.2.1. 数据映射关系#
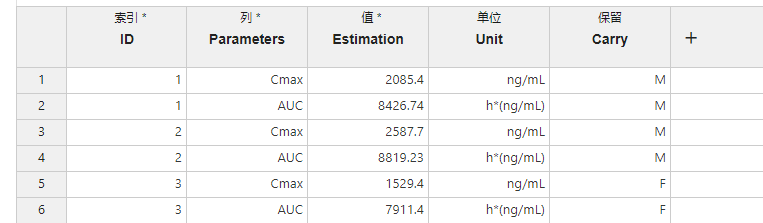
图 2.47 长表转置映射关系示意图#
索引 (必选项,单选):数据的索引。将依据被映射为此项的数据列中的数据值水平转置表格,即拥有同一索引值的数据将在转置后位于同一行上。
列 (必选项,单选):映射为此项的数据将用于生成转置后表格的列及其列名。
值 (必选项,单选):映射为此项的数据将作为转置后表格各列内的数据值。
单位 (可选项,单选):映射为此项的数据将作为转置后表格各列的单位。如果同一个 “列” 值对应多个单位,将以第一个出现的单位为准,转换其他单位至第一个单位。
保留 (可选项,多选):需要在转置后被保留的数据列。如果同一个 “列” 值对应多个保留值,将仅保留第一个出现的值。
2.2.2. 结果#
转置表#
转置后的表格,如 图 2.48 所示。

图 2.48 长表转置转置表示意图#
2.3. 宽表转置#
可将宽表转置为长表。例如可对非房室分析个体参数表格进行转置,以关注某个个体的所有参数结果。
2.3.1. 数据映射关系#
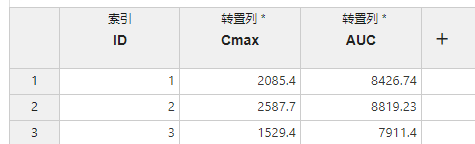
图 2.49 宽表转置映射关系示意图#
索引 (可选项,多选):映射为此项的数据将在转换后作为行索引。
转置列 (必选项,多选):映射为此项的各个数据列的列名及其中的数据将被分别转置入同一列内(即形成类似于
列名:数据值的结果)。
2.3.2. 分析选项#
转置数据选项#
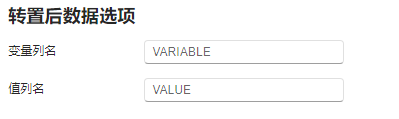
图 2.50 转置数据选项示意图#
变量列名:转置后表格中用于存放原 “转置列” 列名的数据列列名。输入值不能为空,且不能与索引列名、“值列名” 或 “单位列名” 相同。默认值为
VARIABLE。值列名:转置后表格中用于存放原 “转置列” 内数据值的数据列列名。输入值不能为空,且不能与索引列名、“变量列名” 或 “单位列名” 相同。默认值为
VALUE。
转置后单位选项#

图 2.51 转置后单位选项示意图#
结果中输出单位列:若勾选则将在转置后的表格中新增一列以用于存放原 “转置列” 的单位,且勾选后需要填写下方的 “单位列名” 选项。
单位列名:转置后表格中用于存放原 “转置列” 单位的数据列列名。输入值不能为空,且不能与索引列名、“变量列名” 或 “值列名” 相同。仅当勾选 结果中输出单位列 后才会出现此选项。默认值为
UNIT。
2.3.3. 结果#
转置表#
转置后的表格,如 图 2.52 所示。
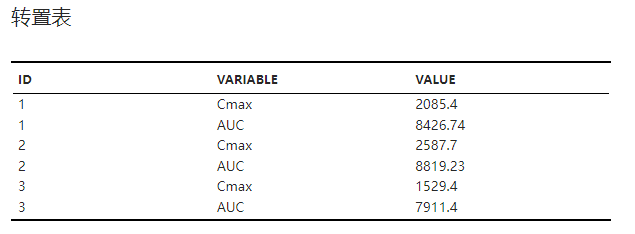
图 2.52 宽表转置转置表示意图#
2.4. BQL 数据处理#
使用此功能可根据自定义的规则来替换或标记低于定量下限(below the quantification limit,BQL)的数据。
2.4.1. 数据映射关系#
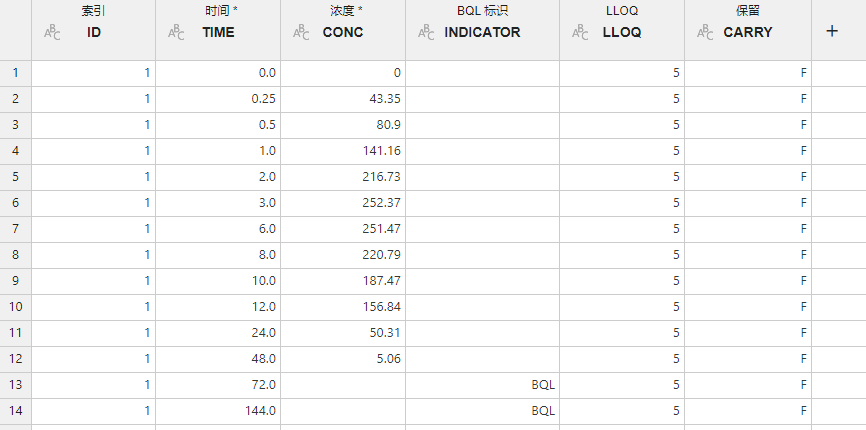
图 2.53 BQL 数据处理映射关系示意图#
索引 (可选项,多选):数据的索引。用于识别个体数据,拥有同样索引值组合的数据将被视为来源于同一个个体。
时间 (必选项,单选):血药浓度观测时间。
浓度 (必选项,单选):血药浓度观测值。
BQL 标识 (可选项,单选):用于标记某观测值是否为 BQL 数据的值。
LLOQ (可选项,单选):定量下限(lower limit of quantification,LLOQ)的值。
保留 (可选项,多选):需要保留的数据列。映射为此项的数据将在处理后的数据集内被保留,否则将被丢弃。
2.4.2. 分析选项#
规则列表#
在此卡片内可填写自定义的替换规则。每条规则的选项内容根据替换方案的不同而有所不同,而在各方案间均相同的选项包括:
BQL 标识码:输入 BQL 数据的标识码,“BQL 标识” 数据中与此处输入值相同的数据将被识别为 BQL 数据。若未录入或映射 “BQL 标识” 数据,则将匹配 “浓度” 数据中与此处输入值相同的数据。
同作用于小于 LLOQ 的数据:勾选后,此条替换规则将同作用于血药浓度小于 LLOQ 值的数据。默认不勾选。
替换方案:决定此条规则的替换方案,可选项包括
条件替换、全部替换以及设为 LLOQ 并新增标识列。当替换方案为条件替换时,将根据 Tmax 的值(达峰时间,即峰浓度对应的观测时间)以及 BQL 数据的出现顺序来进行替换。当替换方案为全部替换时,将会替换所有 BQL 数据为统一值。当替换方案为设为 LLOQ 并新增标识列时,会将所有 BQL 数据设为 LLOQ 的值并输出至输出列中。同时生成一列标识列,其中使用1标记原 BQL 数据,使用0标记其他数据。不同的选项也将影响此条规则内其他选项的内容,详见下文。默认值为条件替换。
当替换方案选择 条件替换 时,后续选项包括(图 2.54):
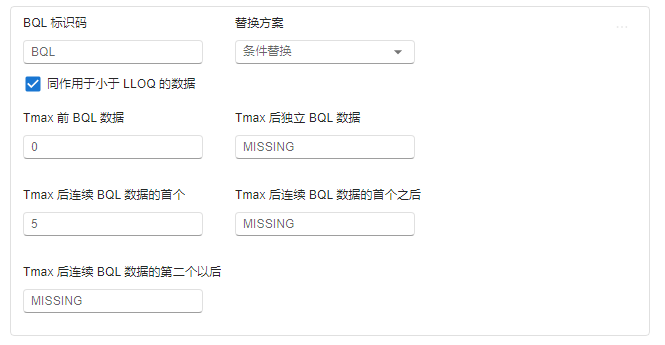
图 2.54 条件替换选项示意图#
Tmax 前 BQL 数据:输入 Tmax 前 BQL 数据的替换值。必填项。
Tmax 后独立 BQL 数据:输入 Tmax 后独立的 BQL 数据(不与其他 BQL 数据相连)的替换值。必填项。
Tmax 后连续 BQL 数据的首个:输入 Tmax 后连续 BQL 数据(至少两个)中首个 BQL 数据的替换值。必填项。
Tmax 后连续 BQL 数据的首个之后:输入 Tmax 后连续 BQL 数据中首个 BQL 数据之后的各个 BQL 数据的替换值。必填项。
Tmax 后连续 BQL 数据的第二个之后:输入 Tmax 后连续 BQL 数据中第二个 BQL 数据之后所有观测值的替换值。非必填项。
备注
为了计算 Tmax 的值,我们将会对每个个体的数据按照观测时间的先后进行排序。如果排序后存在多个 Tmax 值,则以第一个为准。
当替换方案选择 全部替换 时,后续选项包括(图 2.56):
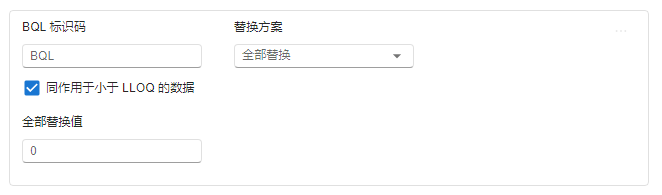
图 2.56 全部替换选项示意图#
全部替换值:输入对于所有 BQL 数据的替换值。必填项。
当替换方案选择 设为 LLOQ 并新增标识列 时,后续选项包括(图 2.57):
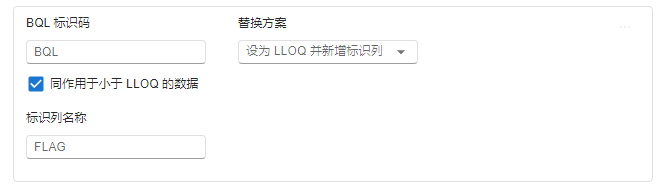
图 2.57 设为 LLOQ 并新增标识列选项示意图#
标识列名称:用于标识 BQL 数据的数据列列名。必填项。
我们可以点击规则下方的 “添加替换规则” 按钮来新增一条规则。当存在多条规则时,可以点击规则卡片右上角的  来更改规则的先后顺序或删除某条规则(图 2.58)。
来更改规则的先后顺序或删除某条规则(图 2.58)。
备注
多条替换规则逐条执行且互相独立,前一条的处理结果不影响后一条的结果。
图 2.58 添加规则按钮与其他操作按钮位置示意图#
LLOQ 选项#

图 2.59 LLOQ 选项示意图#
使用固定 LLOQ 水平:勾选后将为所有个体使用固定的 LLOQ 值,且需要填入下述的 “LLOQ 水平” 值。默认不勾选
LLOQ 水平:输入固定 LLOQ 水平的值。必填项。
备注
固定 LLOQ 水平的比较优先级高于原数据中的 “LLOQ” 数据。即如果勾选了 使用固定 LLOQ 水平,则将不再使用原数据中的 LLOQ 值。
输出选项#

图 2.60 输出选项示意图#
输出列名称:用于输出处理后血药浓度数据的数据列列名。必填项。
保留原始浓度列:勾选后将在原数据的基础上增加一列作为输出列,否则将直接替换原先被映射为 “浓度” 的列。默认勾选。
2.4.3. 结果#
替换结果#
根据替换规则生成的处理后数据集,如 图 2.61 所示。
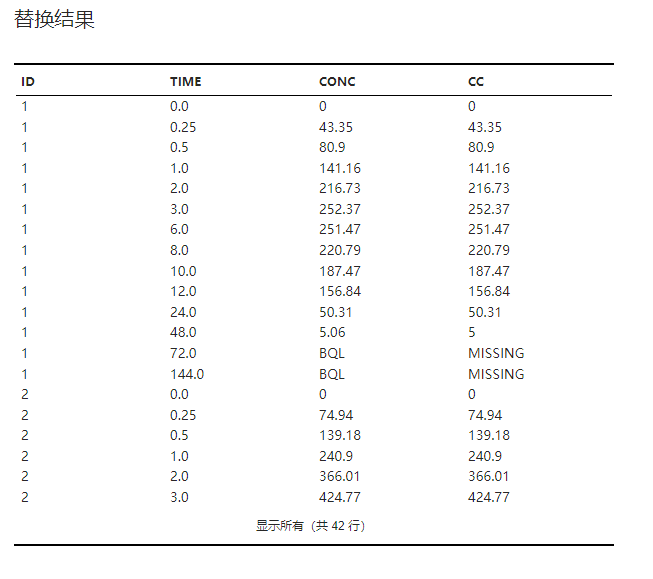
图 2.61 替换结果表格示意图#
2.5. 数据排序#
使用此功能可以按照索引值的大小对数据集进行排序。
2.5.1. 数据映射关系#
图 2.62 数据排序映射关系示意图#
索引 (必选项,多选):用于排序的数据索引。如果有多个索引列,则将根据它们从左到右的顺序依次对数据进行排序。
保留 (可选项,多选):需要保留的数据列。映射为此项的数据将在排序后的数据集内被保留,否则将被丢弃。
2.5.2. 分析选项#
排序选项#
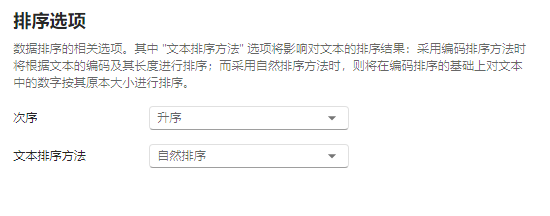
图 2.63 排序选项示意图#
次序:排序的次序。可选项为
升序与降序。默认选项为升序。文本排序方法:文本排序的方法。可选项为
自然排序与编码排序。两者的区别主要在于对文本中数字的排序方法不同:若选择编码排序,则将根据文本原始的编码以及长度进行排序;若选择自然排序,则将在编码排序的基础上按数字原本的大小进行排序,样例可参见 图 2.64。默认选项为自然排序。
备注
关于自然排序的详情可参见:natsort: Simple yet flexible natural sorting in Python。

图 2.64 两种排序方法的区别示意图#
2.5.3. 结果#
排序结果#
排序后的数据集,如 图 2.65 所示:
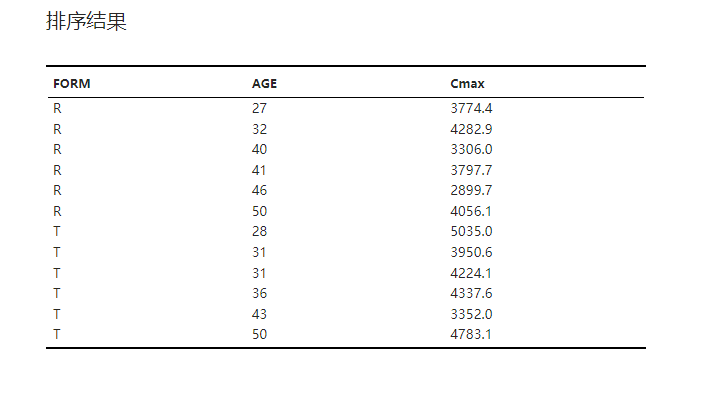
图 2.65 排序结果示意图#
2.6. 数据筛选#
使用此功能可以筛选出符合条件的数据行。
2.6.1. 数据映射关系#
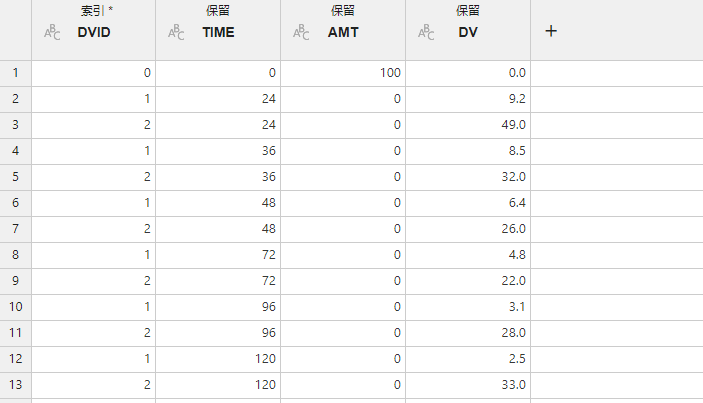
图 2.66 数据筛选映射关系示意图#
索引 (必选项,多选):数据的索引,其中的值可以作为筛选值。
保留 (可选项,多选):需要保留的数据列。映射为此项的数据将在筛选后的数据集内被保留,否则将被丢弃。
2.6.2. 分析选项#
筛选规则#
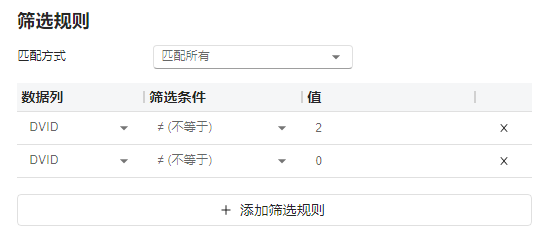
图 2.67 筛选规则选项示意图#
匹配方式:对筛选规则的匹配方式。可选项为
匹配所有或匹配任意。当选择匹配所有时,仅会筛选出同时满足所有筛选规则的数据;当选择匹配任意时,只要数据满足任意一条筛选规则,就会被纳入筛选结果。默认选项为匹配所有。规则列表:用于输入筛选规则,每条筛选规则由以下三部分组成:
数据列:选择此条筛选规则对应的数据列。可选项为所有映射为 “索引” 的列。
筛选条件:此条筛选规则的筛选条件。可选项根据 “数据列” 的类型不同而有所不同,具体可详见下表。
值:在筛选时被比较的筛选值。
数据列类型 |
可用的筛选条件 |
|---|---|
数字 |
=(等于)、≠(不等于)、>(大于)、≥(大于等于)、 |
文本 |
等于、不等于、开头是、结尾是、 |
通过点击 “+ 添加筛选规则” 按钮可以增加多条筛选规则。点击筛选规则右侧的  按钮可以删去此条规则。
按钮可以删去此条规则。
2.6.3. 结果#
筛选结果#
根据筛选规则筛选得到的数据,如 图 2.68 所示:
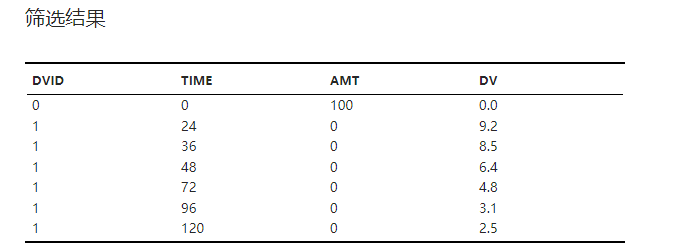
图 2.68 筛选结果表格示意图#
2.7. 数据合并#
使用此功能可用合并两个具有相同索引的数据集。
2.7.1. 数据映射关系#
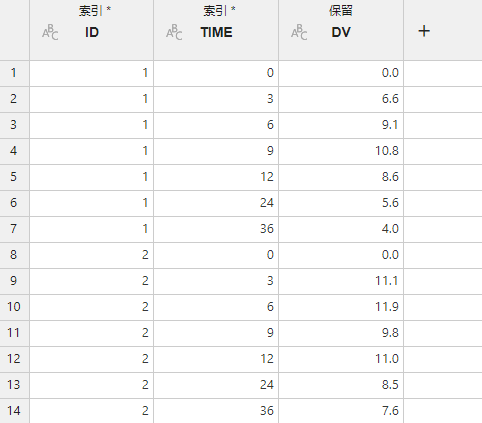
图 2.69 数据合并映射关系示意图#
索引 (必选项,多选):用于数据合并的索引列。
保留 (可选项,多选):需要保留的数据列。映射为此项的数据将在合并后的数据集内被保留,否则将被丢弃。
重要
索引列在左表与右表中的列名与列类型必须相同。
2.7.2. 分析选项#
合并选项#
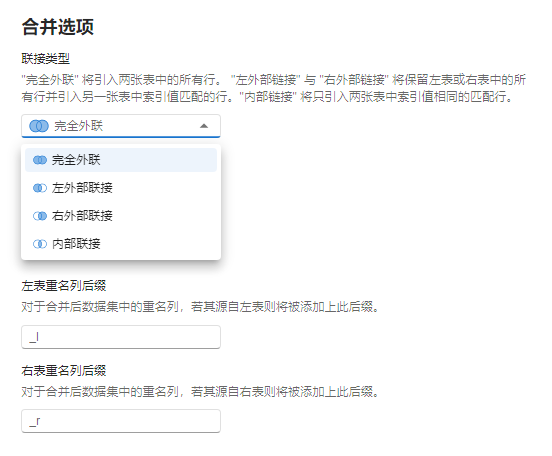
图 2.70 合并选项示意图#
联接类型:选择左表与右表联接的类型。可选项为
完全外联、左外部联接、右外部联接、内部联接。完全外联将引入两张表中的所有行;左外部链接与右外部链接将保留左表或右表中的所有行并引入另一张表中索引值相同的行;内部链接将只引入两张表中索引值相同的行。四者的差异可参考 图 2.71。默认选项为完全外联。
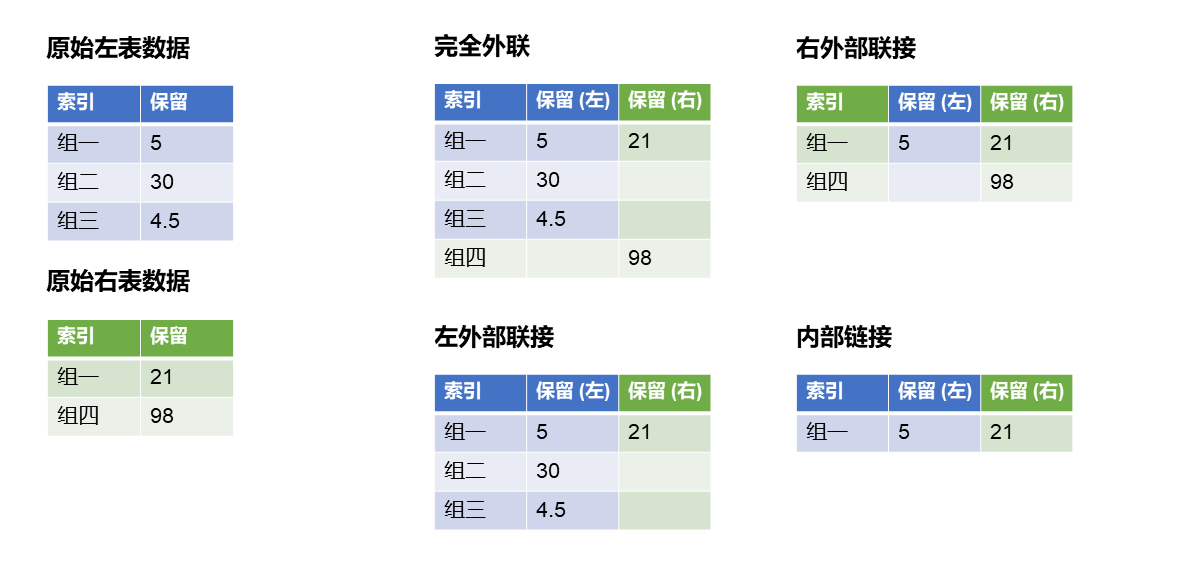
图 2.71 联接类型的区别示意图#
左表重名列后缀:对于合并后数据集中的重名列,若其源自左表则将被添加上此后缀。例如左表与右表中均有名为
DV的列,当设置左表重名列后缀为_l时,合并后数据集中原左表的DV列将被重命名为DV_l。右表重名列后缀:对于合并后数据集中的重名列,若其源自右表则将被添加上此后缀。
备注
左表与右表的重名列后缀应不同。且加入后缀后的列名应与原数据中其他列名不同。
2.7.3. 结果#
合并表#
左表与右表合并后的结果表格,如 图 2.72 所示:
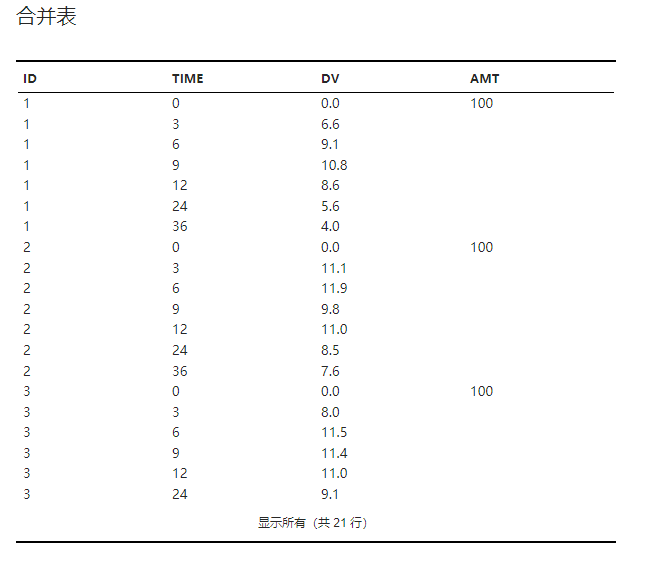
图 2.72 合并表示意图#